1. Introduction and KNN
What is ML?
Definition
- A computer program is said to
- learn from experience
E - with respect to some class of tasks
T - and performance measure
P - IF its performance at tasks in
T, as measured byP, improves withE.
Note
Design algorithms that:
- improves their performance
- on some task
- with experience (training data)
Categories
Supervised Learning
- Given labeled data, find a function taht goes from that data to label.
- Given , predict construct a prediction rule
Discrete Labels
Binary classification: 2 categoriesMulti-class classification: more than 2 categories
Continuous Labels
Regression: Analyze the relationship between dependent variables and independent variables
Unsupervised Learning
- Given , learn
- learning without a teacher
- e.g. clustering and PCA
Good ML Algorithm
- SHOULD: Generalize well on test data
- SHOULD NOT: Overfit the training data
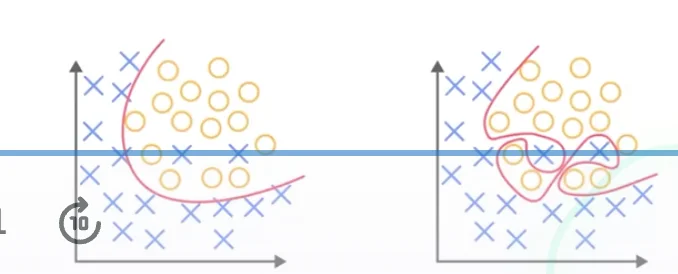
KNN
- similar points are likely to have the same labels
- Dataset:
- New Datapoint:
- Prediction:

Algorithm
- Find the top
nearest, under metric - Return the most common label among these neighbors
- For regession, the average value of the neighbors is returned
How to measure closeness?
- Rely on a distance metric.
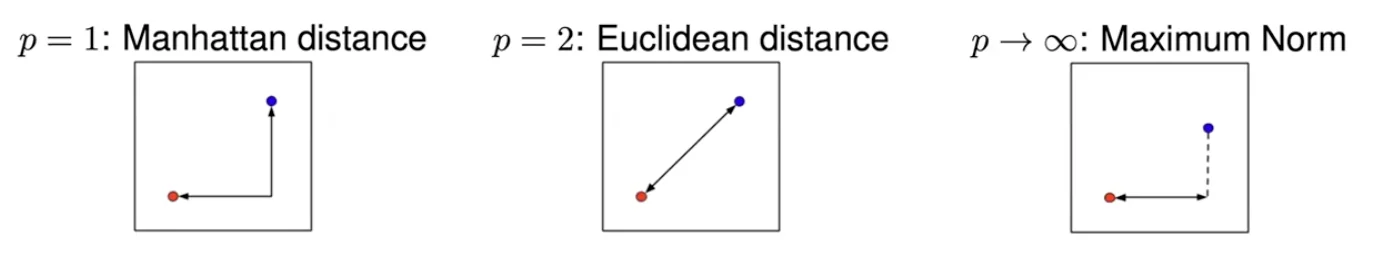
Minkowski Distance
- the common metric
- For each dimension, calculate the distance between
xandz d: distance- Special cases

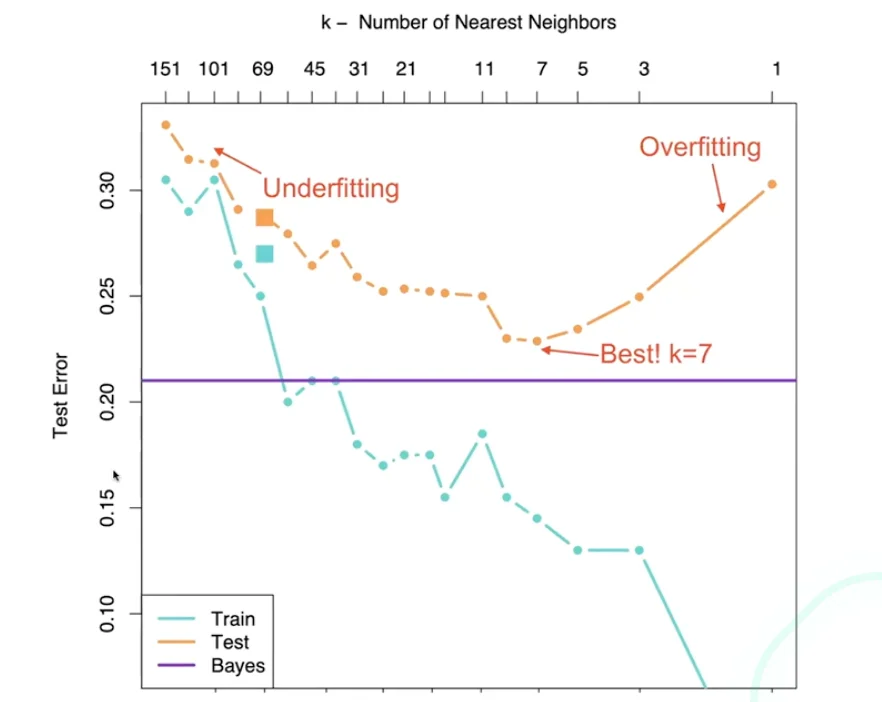
The choice of K
- Small K -> label has noise
- Large K -> The boundary becomes smoother
Caution
Very large K may make the algorithm to include examples that are really far off.
What’s the best K
Issues
- Memory issue
- sensitive to outliers and easily fooled by irrelevant attributes
- 0 training time; computationally expensive O(Nd)
- If
dis large -> curse of dimensionality
Hyperparameters
- We DO NOT CHOOSE hyperparameters to minimize training or testing errors
Solution
- randomly take out
10~50%of training and use it instead of the test set to estimate test error. Validation Set: the set taking out to verify the test set.
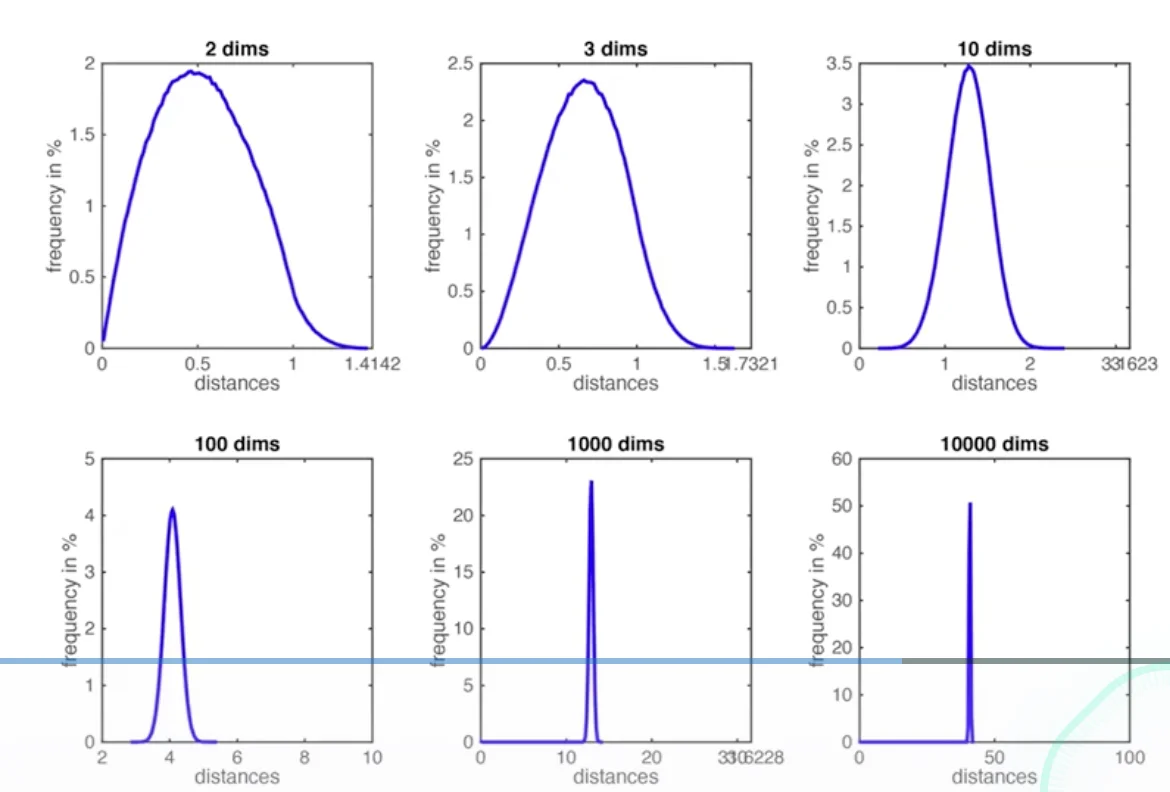
Curse of Dimensionality

- Assume data lives in , and all training data is sampled uniformly. And we observe the neighbors fall inside the small cube
- The probability of sampling a point inside the small cube is roughly
-
: The total number of data that we sample
-
: nearest neighbors fall inside the small cube.
-
If and , how big is
-
d = 2, l = 0.1
-
d = 10, l = 0.63
-
d = 100, l = 0.955
-
d = 1000, l = 0.9954
Caution
When is large, the nearest neighbors will be almost all over the place
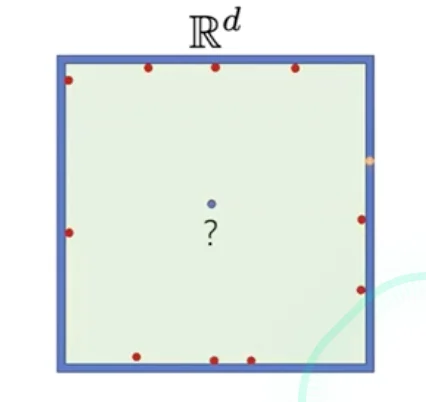
- In high dimensional space, you don’t have neighbors anymore
Data may have low dimensional structure
- High dimensional space may contain low dimensional subspaces
- Your data may lie in a low dimensional subspace or its low dimensional
KNN vs. Linear Classifier
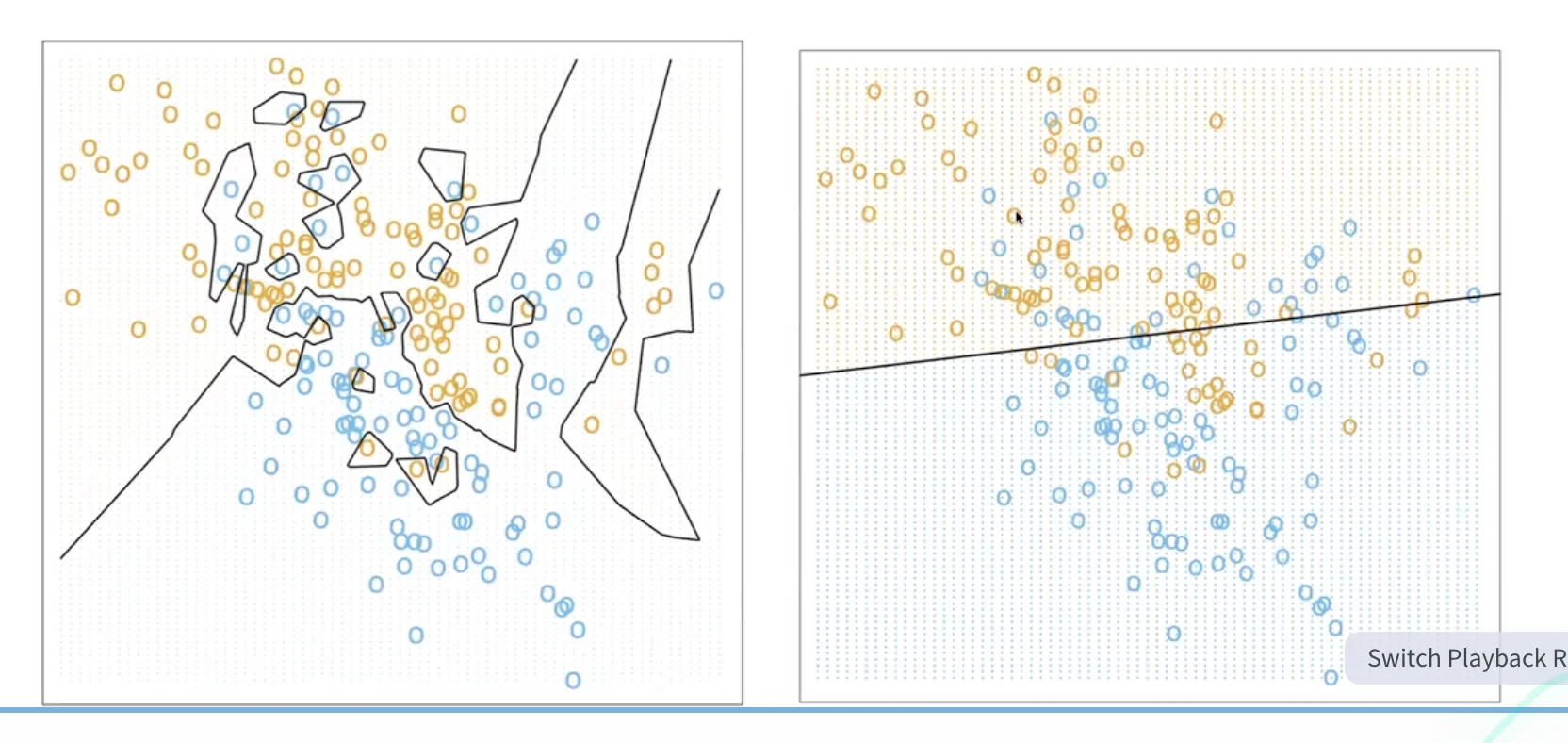
KNN Summary
- KNN is
simpleandeffectiveif thedistance reflects dissimilarity - works when data is low-dimensional
- DOES NOT work for high-dimensional data due to sparsity.