4. Linear Regression
Regression
f : X → Y f: X \rightarrow Y f : X → Y Approach
Choose parameterized form for P ( Y ∣ X , w ) P(Y \mid X, w) P ( Y ∣ X , w )
Derive learning algorithm as MLE or MAP
Parameterized form for P ( Y ∣ X , w ) P(Y \mid X, w) P ( Y ∣ X , w )
Y is some deterministic f ( X ) f(X) f ( X )
y = f ( x ) + ϵ w h e r e ϵ ∼ N ( 0 , σ 2 ) y = f(x) + \epsilon \quad where \ \epsilon \sim \mathcal{N}(0, \sigma^2) y = f ( x ) + ϵ w h ere ϵ ∼ N ( 0 , σ 2 )
Therefore, Y is a r.v. that follows
p ( y ∣ x ) = N ( f ( x ) , σ 2 ) p(y \mid x) = \mathcal{N}(f(x), \sigma^2) p ( y ∣ x ) = N ( f ( x ) , σ 2 ) Consider Linear Regression
f ( x ) = w T x + w 0 ( w ∈ R d , w 0 ∈ R ) p ( y ∣ x ) = N ( w T x + w 0 , σ 2 ) \begin{align*}
&f(x) = w^Tx + w_0 \quad (w \in \R^d, w_0 \in \R) \\
&p(y \mid x) = N(w^Tx + w_0, \sigma^2)
\end{align*} f ( x ) = w T x + w 0 ( w ∈ R d , w 0 ∈ R ) p ( y ∣ x ) = N ( w T x + w 0 , σ 2 )
Let x = [ x 1 ] , w = [ w w 0 ] x = \begin{bmatrix}x \\ 1\end{bmatrix}, w = \begin{bmatrix}w \\ w_0\end{bmatrix} x = [ x 1 ] , w = [ w w 0 ]
p ( y ∣ x ) = N ( w T x , σ 2 ) p(y \mid x) = N(w^Tx, \sigma^2) p ( y ∣ x ) = N ( w T x , σ 2 ) MLE
Quardratic Form
First, expand the prediction function
p ( y ∣ x , w ) = N ( w T x , σ 2 ) = 1 2 π σ 2 e − ( y − w ⊺ x ) 2 2 σ 2 \begin{align*}
p(y \mid x, w) &= N(w^Tx, \sigma^2) \\
&= \frac{1}{\sqrt{2 \pi \sigma^2}} e^{-\frac{(y - w^\intercal x)^2}{2\sigma^2}}
\end{align*} p ( y ∣ x , w ) = N ( w T x , σ 2 ) = 2 π σ 2 1 e − 2 σ 2 ( y − w ⊺ x ) 2
Then, calculate the w w w w ^ M L E \hat{w}^{MLE} w ^ M L E
w ^ M L E = arg max w ∏ i = 1 N 1 2 π σ 2 e − ( y ( i ) − w ⊺ x ( i ) ) 2 2 σ 2 = arg max w ∑ i = 1 N log 1 2 π σ 2 + log e − ( y ( i ) − w ⊺ x ( i ) ) 2 2 σ 2 = arg max w ∑ i = 1 N log 1 2 π σ 2 − ( y ( i ) − w ⊺ x ( i ) ) 2 2 σ 2 ( Remove irrelevant term and flip sign ) = arg min w ∑ i = 1 N ( y ( i ) − w ⊺ x ( i ) ) 2 2 σ 2 = arg min w ∑ i = 1 N ( y ( i ) − w ⊺ x ( i ) ) 2 = arg min w ∑ i = 1 N ( y ( i ) − w ⊺ x ( i ) ) 2 ( Take the average ) = arg min w ∑ i = 1 N ( y ( i ) − w ⊺ x ( i ) ) 2 \begin{align*}
\hat{w}^{MLE} &= \argmax_w \prod^N_{i = 1} \frac{1}{\sqrt{2 \pi \sigma^2}} e^{-\frac{(y^{(i)} - w^\intercal x^{(i)})^2}{2\sigma^2}} \\
&= \argmax_w \sum^N_{i = 1} \log \frac{1}{\sqrt{2 \pi \sigma^2}} + \log e^{-\frac{(y^{(i)} - w^\intercal x^{(i)})^2}{2\sigma^2}} \\
&= \argmax_w \sum^N_{i = 1} \log \frac{1}{\sqrt{2 \pi \sigma^2}} -\frac{(y^{(i)} - w^\intercal x^{(i)})^2}{2\sigma^2} \quad (\text{Remove irrelevant term and flip sign})\\
&= \argmin_w \sum^N_{i = 1} \frac{(y^{(i)} - w^\intercal x^{(i)})^2}{2\sigma^2} \\
&= \argmin_w \sum^N_{i = 1} (y^{(i)} - w^\intercal x^{(i)})^2 \\
&= \argmin_w \sum^N_{i = 1} (y^{(i)} - w^\intercal x^{(i)})^2 \quad (\text{Take the average})\\
&= \argmin_w \sum^N_{i = 1} (y^{(i)} - w^\intercal x^{(i)})^2 \\
\end{align*} w ^ M L E = w arg max i = 1 ∏ N 2 π σ 2 1 e − 2 σ 2 ( y ( i ) − w ⊺ x ( i ) ) 2 = w arg max i = 1 ∑ N log 2 π σ 2 1 + log e − 2 σ 2 ( y ( i ) − w ⊺ x ( i ) ) 2 = w arg max i = 1 ∑ N log 2 π σ 2 1 − 2 σ 2 ( y ( i ) − w ⊺ x ( i ) ) 2 ( Remove irrelevant term and flip sign ) = w arg min i = 1 ∑ N 2 σ 2 ( y ( i ) − w ⊺ x ( i ) ) 2 = w arg min i = 1 ∑ N ( y ( i ) − w ⊺ x ( i ) ) 2 = w arg min i = 1 ∑ N ( y ( i ) − w ⊺ x ( i ) ) 2 ( Take the average ) = w arg min i = 1 ∑ N ( y ( i ) − w ⊺ x ( i ) ) 2
Therefore, we derive that, the MLE is the minimization of the Ordinary Least Squares (OLS)
l ( w ) = 1 N ∑ i = 1 N ( y ( i ) − w ⊺ x ( i ) ) 2 l(w) = \frac{1}{N}\sum^N_{i = 1} (y^{(i)} - w^\intercal x^{(i)})^2 l ( w ) = N 1 i = 1 ∑ N ( y ( i ) − w ⊺ x ( i ) ) 2 Matrix Form
let y = [ y ( i ) ⋮ y ( N ) ] , X = [ x ( i ) ⊺ ⋮ x ( N ) ⊺ ] y = \begin{bmatrix} y^{(i)} \\ \vdots \\y^{(N)}\end{bmatrix}, \quad X = \begin{bmatrix}x^{(i)\intercal} \\ \vdots \\ x^{(N)\intercal}\end{bmatrix} y = y ( i ) ⋮ y ( N ) , X = x ( i ) ⊺ ⋮ x ( N ) ⊺
w = arg min w l ( w ) = arg min w 1 N ∑ i = 1 N ( y ( i ) − w ⊺ x ( i ) ) 2 = arg min w ( y − X w ) T ( y − X w ) = arg min w ( y ⊺ y − ( X w ) ⊺ y − y ⊺ X w + w ⊺ X ⊺ X w ) = arg min w ( y ⊺ y − 2 y ⊺ X w + ( X w ) ⊺ X w ) ∂ l ∂ w = − 2 y ⊺ X + X ⊺ X w + ( X w ) ⊺ X = 0 0 = − 2 y ⊺ X + 2 X ⊺ X w X ⊺ y = X ⊺ X w ( X ⊺ X ) − 1 X ⊺ y = w \begin{align*}
w &= \argmin_w l(w) \\
&= \argmin_w \frac{1}{N} \sum^N_{i = 1} (y^{(i)} - w^\intercal x^{(i)})^2 \\
&= \argmin_w (y - Xw)^T(y - Xw) \\
&= \argmin_w (y^\intercal y - (Xw)^\intercal y - y^\intercal Xw + w^\intercal X^\intercal Xw) \\
&= \argmin_w (y^\intercal y - 2y^\intercal Xw + (Xw)^\intercal Xw) \\
\frac{\partial l}{\partial w}&= - 2y^\intercal X + X^\intercal Xw + (Xw)^\intercal X = 0 \\
0 &= -2y^\intercal X + 2X^\intercal Xw \\
X^\intercal y &= X^\intercal Xw \\
(X^\intercal X)^{-1}X^\intercal y &= w \\
\end{align*} w ∂ w ∂ l 0 X ⊺ y ( X ⊺ X ) − 1 X ⊺ y = w arg min l ( w ) = w arg min N 1 i = 1 ∑ N ( y ( i ) − w ⊺ x ( i ) ) 2 = w arg min ( y − Xw ) T ( y − Xw ) = w arg min ( y ⊺ y − ( Xw ) ⊺ y − y ⊺ Xw + w ⊺ X ⊺ Xw ) = w arg min ( y ⊺ y − 2 y ⊺ Xw + ( Xw ) ⊺ Xw ) = − 2 y ⊺ X + X ⊺ Xw + ( Xw ) ⊺ X = 0 = − 2 y ⊺ X + 2 X ⊺ Xw = X ⊺ Xw = w
Therefore, we derive that:
w = ( X ⊺ X ) − 1 X ⊺ y w = (X^\intercal X)^{-1}X^\intercal y w = ( X ⊺ X ) − 1 X ⊺ y MAP
w ^ M A P = arg max w P ( w ∣ x ( 1 ) , y ( 1 ) , … , x ( N ) , y ( N ) ) = arg max w P ( x ( 1 ) , y ( 1 ) , … , x ( N ) , y ( N ) ∣ w ) P ( w ) P ( x ( 1 ) , y ( 1 ) , … , x ( N ) , y ( N ) ) = arg max w P ( x ( 1 ) , y ( 1 ) , … , x ( N ) , y ( N ) ∣ w ) P ( w ) = arg max w P ( y ( 1 ) , … , y ( N ) ∣ x ( 1 ) , … , x ( N ) , w ) P ( x ( 1 ) , … , x ( N ) ∣ w ) P ( w ) = arg max w ∏ i = 1 N [ P ( y ( i ) ∣ x ( i ) , w ) ] P ( w ) Assume 0-mean Gaussian prior 1 2 π τ 2 e − w ⊺ w 2 τ 2 = arg max w ∑ i = 1 N log P ( y ( i ) ∣ x ( i ) , w ) + log P ( w ) = arg min w 1 2 σ 2 ∑ i = 1 N P ( w ⊺ x ( i ) − y ( i ) ) − w ⊺ w 2 τ 2 Let λ = σ 2 N τ 2 and remove 1 2 = arg min w 1 N ∑ i = 1 N ( w ⊺ x ( i ) − y ( i ) ) 2 + λ ∣ ∣ w ∣ ∣ 2 2 \begin{align*}
\hat{w}^{MAP} &= \argmax_w P(w \mid x^{(1)}, y^{(1)}, \dots, x^{(N)}, y^{(N)}) \\
&= \argmax_w \frac{P(x^{(1)}, y^{(1)}, \dots, x^{(N)}, y^{(N)} \mid w)P(w)}{P(x^{(1)}, y^{(1)}, \dots, x^{(N)}, y^{(N)})} \\
&= \argmax_w P(x^{(1)}, y^{(1)}, \dots, x^{(N)}, y^{(N)} \mid w)P(w) \\
&= \argmax_w P(y^{(1)}, \dots, y^{(N)} \mid x^{(1)}, \dots, x^{(N)}, w)P(x^{(1)}, \dots, x^{(N)} \mid w)P(w) \\
&= \argmax_w \prod^N_{i= 1} \left[ P(y^{(i)} \mid x^{(i)}, w) \right]P(w) \\
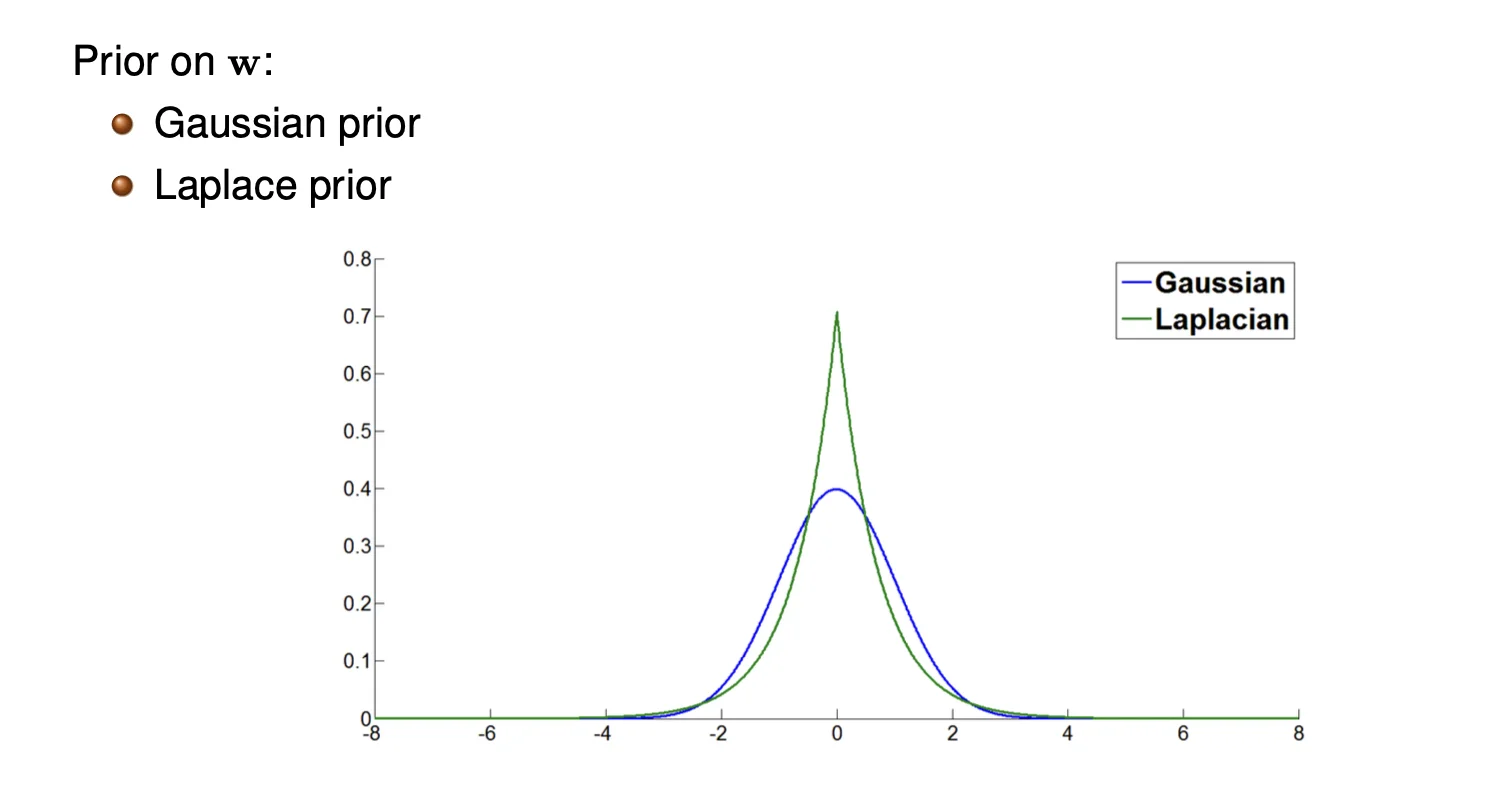
&\text{Assume 0-mean Gaussian prior } \frac{1}{\sqrt{2 \pi \tau^2}}e^{-\frac{w^\intercal w}{2 \tau^2}}\\
&= \argmax_w \sum^N_{i=1} \log P(y^{(i)} \mid x^{(i)}, w) + \log P(w) \\
&= \argmin_w \frac{1}{2\sigma^2} \sum^N_{i=1} P(w^\intercal x^{(i)} - y^{(i)}) -\frac{w^\intercal w}{2 \tau^2} \\
&\text{Let }\lambda = \frac{\sigma^2}{N\tau^2} \text{ and remove } \frac{1}{2} \\
&= \argmin_w \frac{1}{N} \sum^N_{i = 1} (w^\intercal x^{(i)} - y^{(i)})^2 + \lambda ||w||_2^2
\end{align*} w ^ M A P = w arg max P ( w ∣ x ( 1 ) , y ( 1 ) , … , x ( N ) , y ( N ) ) = w arg max P ( x ( 1 ) , y ( 1 ) , … , x ( N ) , y ( N ) ) P ( x ( 1 ) , y ( 1 ) , … , x ( N ) , y ( N ) ∣ w ) P ( w ) = w arg max P ( x ( 1 ) , y ( 1 ) , … , x ( N ) , y ( N ) ∣ w ) P ( w ) = w arg max P ( y ( 1 ) , … , y ( N ) ∣ x ( 1 ) , … , x ( N ) , w ) P ( x ( 1 ) , … , x ( N ) ∣ w ) P ( w ) = w arg max i = 1 ∏ N [ P ( y ( i ) ∣ x ( i ) , w ) ] P ( w ) Assume 0-mean Gaussian prior 2 π τ 2 1 e − 2 τ 2 w ⊺ w = w arg max i = 1 ∑ N log P ( y ( i ) ∣ x ( i ) , w ) + log P ( w ) = w arg min 2 σ 2 1 i = 1 ∑ N P ( w ⊺ x ( i ) − y ( i ) ) − 2 τ 2 w ⊺ w Let λ = N τ 2 σ 2 and remove 2 1 = w arg min N 1 i = 1 ∑ N ( w ⊺ x ( i ) − y ( i ) ) 2 + λ ∣∣ w ∣ ∣ 2 2
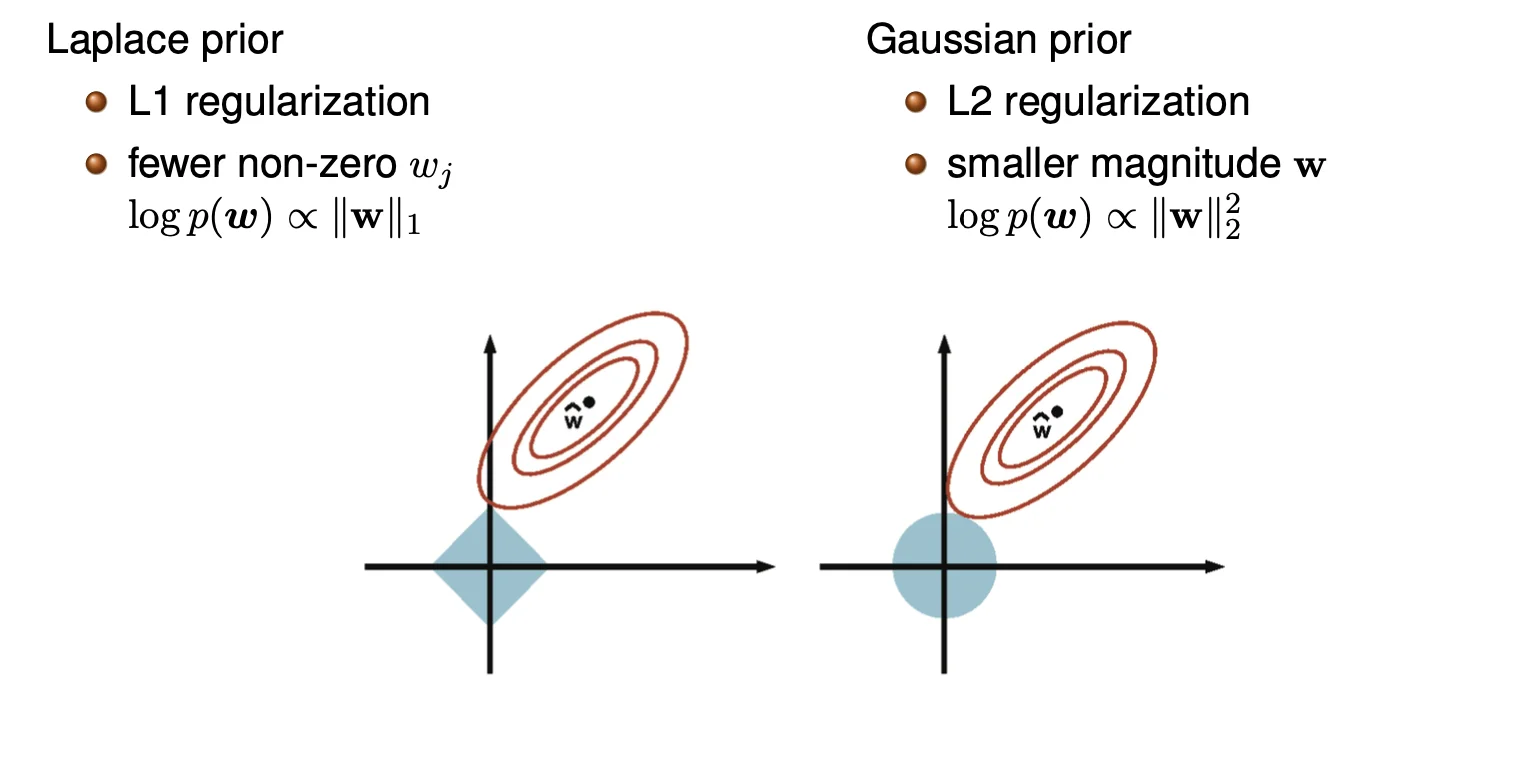
Therefore, with Gaussian prior equivalent to ridge regression (L2), we get closed-form solution:
w = ( X ⊺ X + λ I ) − 1 X ⊺ y w = (X^\intercal X + \lambda I)^{-1} X^\intercal y w = ( X ⊺ X + λ I ) − 1 X ⊺ y If Laplace Prior is assumed instead
Assume Laplace prior for each w j w_j w j
w j : 1 2 b e ∣ w j ∣ b w_j: \frac{1}{2b} e ^{\frac{|w_j|}{b}} w j : 2 b 1 e b ∣ w j ∣
So we can redefine our prior as follows:
p ( w ) = 1 ( 2 b ) d + 1 e − 1 b ∑ i = 1 d ∣ w j ∣ log p ( w ) ∝ ∑ i = 1 d ∣ w j ∣ = ∣ ∣ w ∣ ∣ 1 \begin{align*}
&p(w) = \frac{1}{(2b)^{d + 1}} e^{-\frac{1}{b}\sum^{d}_{i = 1} |w_j|} \\
&\log p(w) \propto \sum^d_{i = 1} | w_j | = ||w||_1
\end{align*} p ( w ) = ( 2 b ) d + 1 1 e − b 1 ∑ i = 1 d ∣ w j ∣ log p ( w ) ∝ i = 1 ∑ d ∣ w j ∣ = ∣∣ w ∣ ∣ 1
Finally, we can derive the w M A P w^{MAP} w M A P
w M A P = arg max w log p ( w ) + ∑ i = 1 N log p ( y ( i ) ∣ x ( i ) , w ) = arg max w c ∣ ∣ w ∣ ∣ 1 + ∑ i = 1 N ( y ( i ) − w ⊺ x ( i ) ) 2 \begin{align*}
w^{MAP} &= \argmax_w \log p(w) + \sum^N_{i = 1} \log p(y^{(i)} \mid x^{(i)}, w) \\
&= \argmax_w c ||w||_1 + \sum^N_{i=1} (y^{(i)} - w^\intercal x^{(i)})^2
\end{align*} w M A P = w arg max log p ( w ) + i = 1 ∑ N log p ( y ( i ) ∣ x ( i ) , w ) = w arg max c ∣∣ w ∣ ∣ 1 + i = 1 ∑ N ( y ( i ) − w ⊺ x ( i ) ) 2