9. Bias Variance
Training Data
- D={(x(i),y(i))}i=1N
- drawn i.i.d. from some distribution (X,Y)
- Assume a regression setting, Y∈R
- For a given x, there may be many y
- Different features may have different labels
- xj(i) in x(i) may not have the same y(i)
Tip
Given a certain x, which y should you predict?
Expected Label (given x∈Rd)
- For a given x∈Rd, the expected label:
yˉ(x)=Ey∣x[Y]=∫yyP(y∣x)dy
Expected Test Error (given hD)
- Now, we have some ML Algorithm (A), which takes the dataset D as an input to generate the predictor hD
hD=A(D)
- With the predictor hD, we can hopefully derive the expected test error as follows:
hˉ(x)=E(x,y)∼P[(hD−y)2]=∫x∫y(hD−y)2P(x,y)dydx
Caution
With this formula, we are still depending on the data distributions
Expected Predictor (given A)
- Assume that:
- A: Linear regression
- D: Sales data from the previous year
- hD: A random variable
- Expected Predictor Given A
hˉ=ED∼PN[hD]=∫DhDP(D)dD
Expected Test Error (given A)
E(x,y)∼P,D∼PN[(hD(x)−y)2]=∫x∫y∫D(hD(x)−y)2P(x,y)P(D)dDdydx
Full Derivation
- Rewrite the formula by plugging hˉ in
Ex,y,D[(hD(x)−y)2]=Ex,y,D[[(hD(x)−hˉ(x))+(hˉ(x)−y)]2]=Ex,D[(hD(x)−hˉ(x))2]+2Ex,y,D[(hD(x)−hˉ(x))(hˉ(x)−y)]+Ex,y[(hˉ(x)−y)2]
- Solve for Ex,y,D[(hD(x)−hˉ(x))(hˉ(x)−y)]
Ex,y,D[(hD(x)−hˉ(x))(hˉ(x)−y)]=Ex,y[ED[hD(x)−hˉ(x)](hˉ(x)−y)]=Ex,y[(ED[hD(x)]−hˉ(x))(hˉ(x)−y)]=Ex,y[(hˉ(x)−hˉ(x))(hˉ(x)−y)]=Ex,y[0]=0
- Solve for Ex,y[(hˉ(x)−y)2]
Ex,y[(hˉ(x)−y)2]=Ex,y[(hˉ(x)−yˉ(x))+(yˉ(x)−y)2]=Ex[(hˉ(x)−yˉ(x))2]+2Ex,y[(hˉ(x)−yˉ(x))(yˉ(x)−y)]++Ex,y[(yˉ(x)−y)2]
- Solve for Ex,y[(hˉ(x)−yˉ(x))(yˉ(x)−y)]
Ex,y[(hˉ(x)−yˉ(x))(yˉ(x)−y)]=Ex[(hˉ(x)−yˉ(x))Ey∣x[yˉ(x)−y]]=Ex[(hˉ(x)−yˉ(x))(yˉ(x)−Ey∣x[y])]=Ex[(hˉ(x)−yˉ(x))(yˉ(x)−yˉ(x))]=Ex[0]=0
- Plug all the solved equations in:
Ex,y,D[[hD(x)−y]2]=Ex,D[(hD(x)−hˉ(x))2]+Ex[(hˉ(x)−yˉ(x))2]+Ex,y[(yˉ(x)−y)2]
Breaking Down the Expected Test Error
Ex,y,D[[hD(x)−y]2]=Ex,D[(hD(x)−hˉ(x))2]+Ex[(hˉ(x)−yˉ(x))2]+Ex,y[(yˉ(x)−y)2]
The expected test error equals
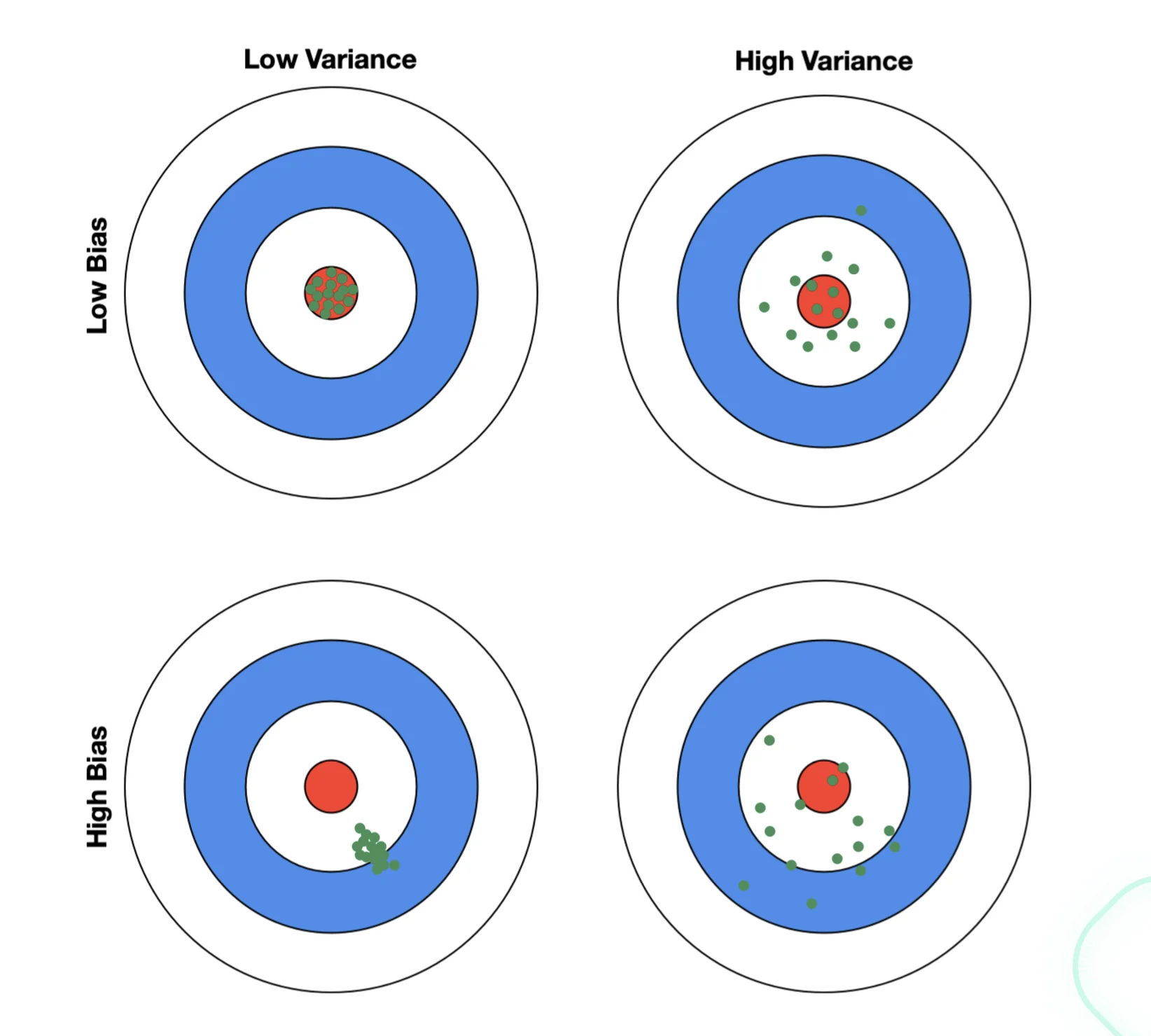
- Variance (due to data randomness)
- Bias (due to model misspecification)
- Irreducible noise (due to inherent randomness in data).
1. Expected Test Error
Ex,y,D[(hD(x)−y)2]
- This is the overall expected test error — how far the model’s predictions hD(x) are from the true values y, averaged over:
- all possible datasets D you could have trained on,
- all possible inputs x, and
- all possible outputs y drawn from the true data distribution.
2. First term:
Ex,D[(hD(x)−hˉ(x))2]
- This measures how much the predictions from different datasets fluctuate around their average prediction hˉ(x).
- In words:
- variance
- how sensitive the model is to the particular training data it saw.
- If this term is large, your model changes a lot depending on the training data (i.e., it’s unstable or overfits).
- If it’s small, your model is consistent across different datasets.
3. Second term:
Ex[(hˉ(x)−yˉ(x))2]
- irreducible
- we may add some more data to resovle this issue
- This measures how far the model’s average prediction hˉ(x) is from the best expected output yˉ(x)=Ey∣x[Y].
- In words:
- bias
- the systematic error of your model.
- If your model’s structure can’t capture the true relationship, this term is large (underfitting).
- If it’s small, your model’s mean prediction is close to the truth.
4. Third term:
Ex,y[(yˉ(x)−y)2]
- This measures how much the true data itself varies around its expected value.
- In words:
- irreducible noise
- randomness or natural variability in the data that no model can ever predict perfectly.
Warning
Any of the error terms can dominate the entire test error
Illustration of Bias and Variance