9.1 Cross Validation and Model Selection
Example: Sine Target
- Let’s say we have the following two models:
Important
Which is better?
- Main question better for what?
Approximation
- Let’s say we want to approximate the following function
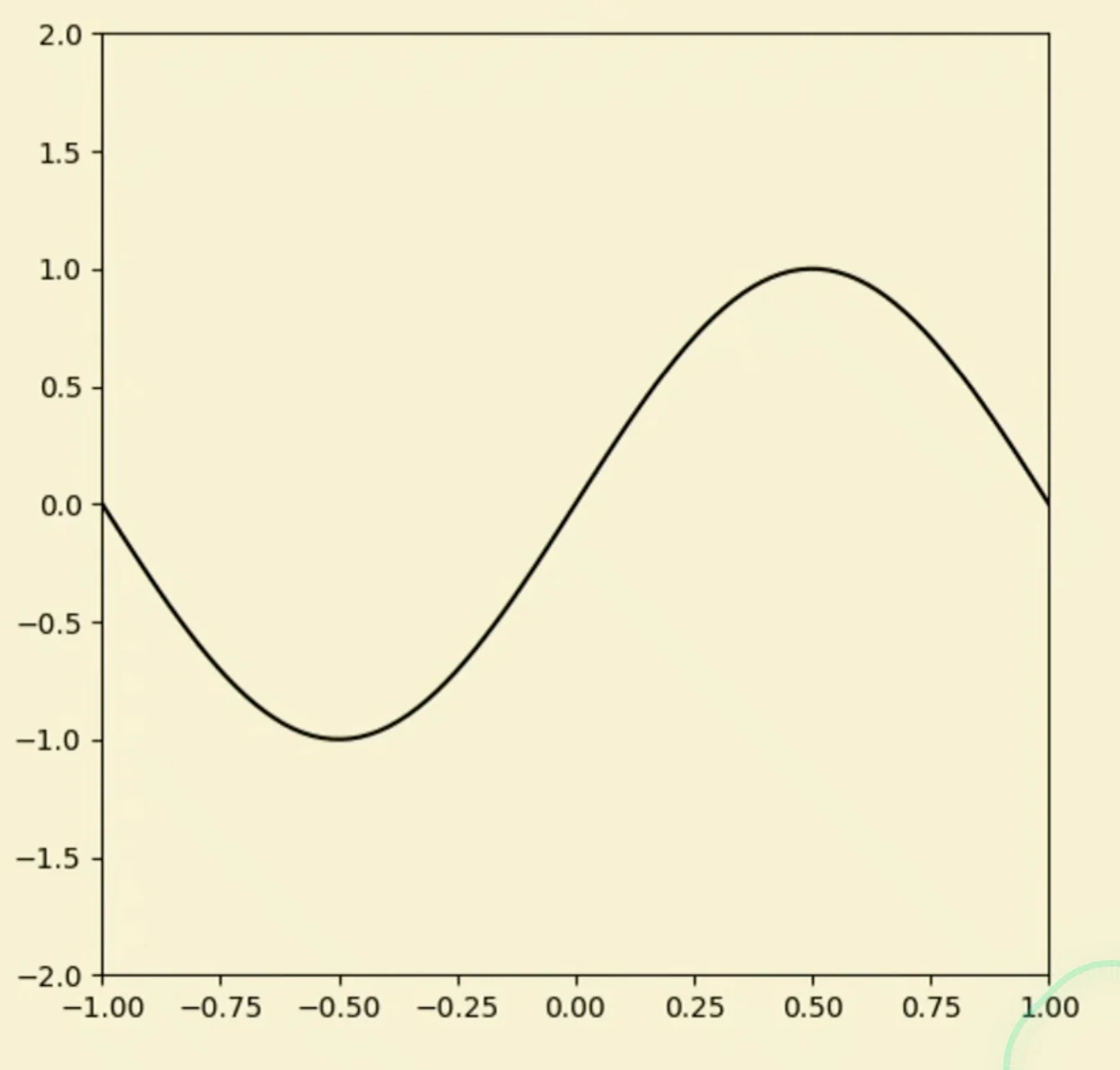
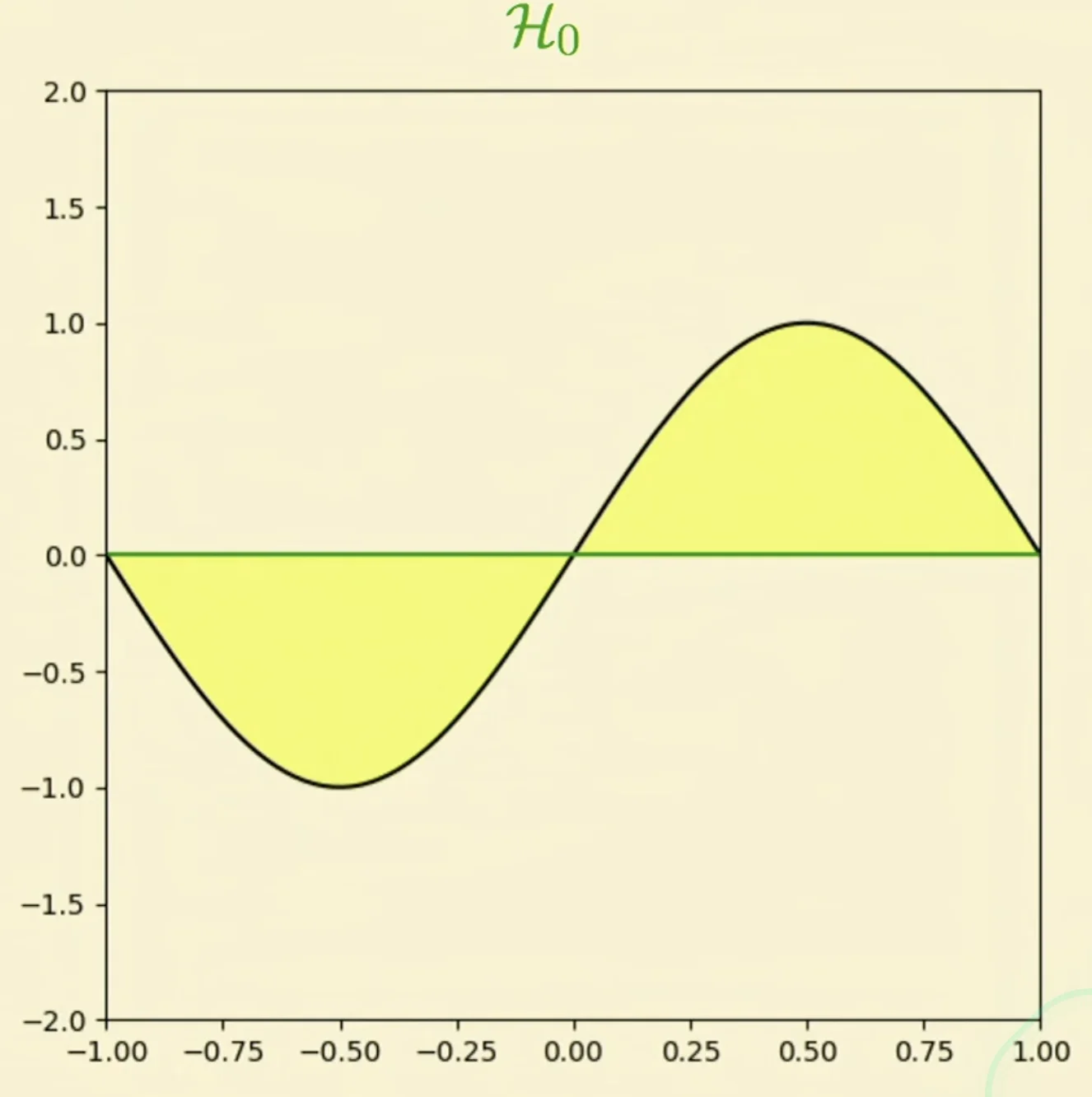
Approximate with
- the yellow part tells us how far we are from the sine function
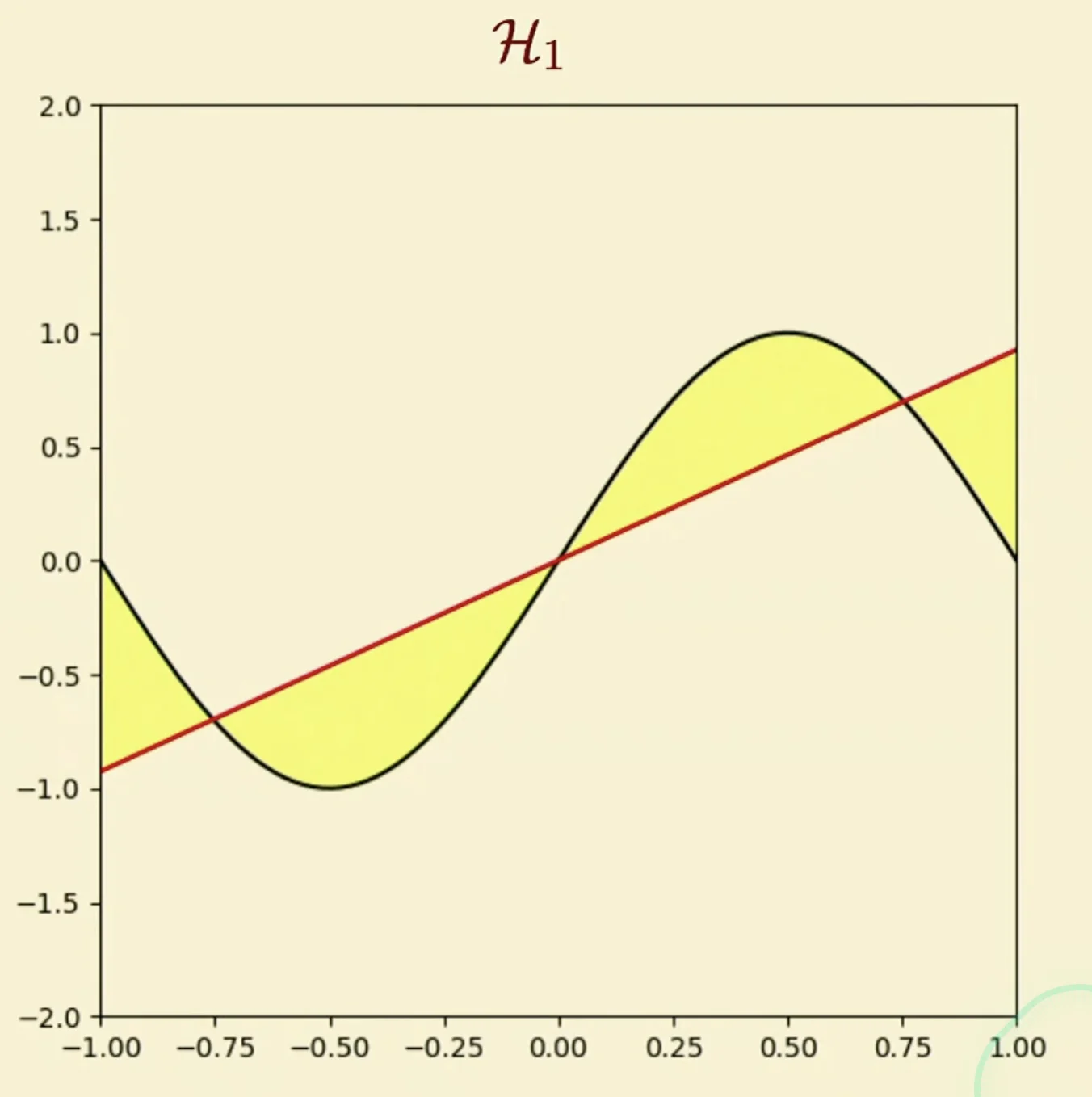
Approximate with
Tip
From the approximation perspective, the linear model wins.
Learning
- For learning, we give our two models two data points and train them
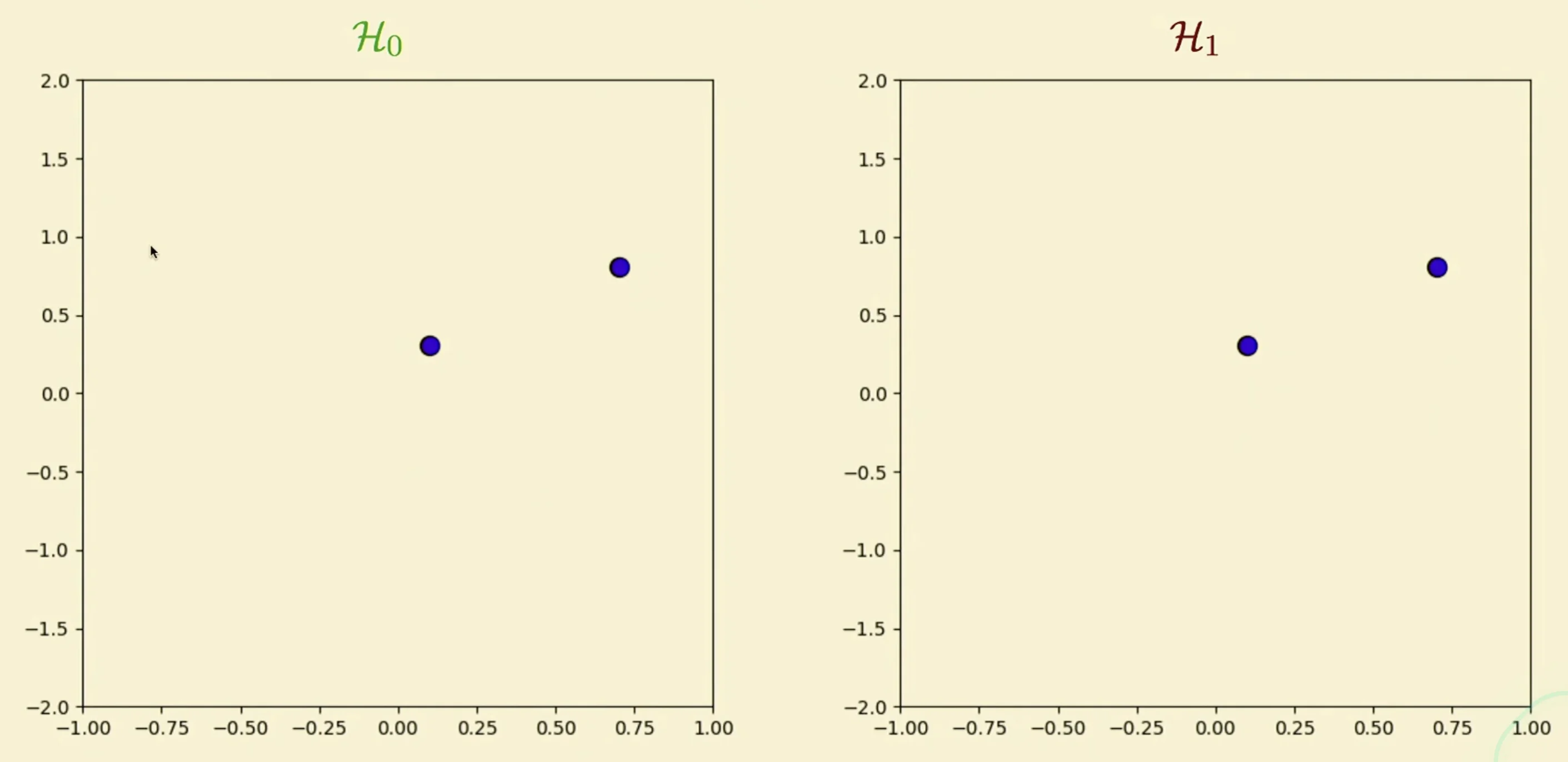
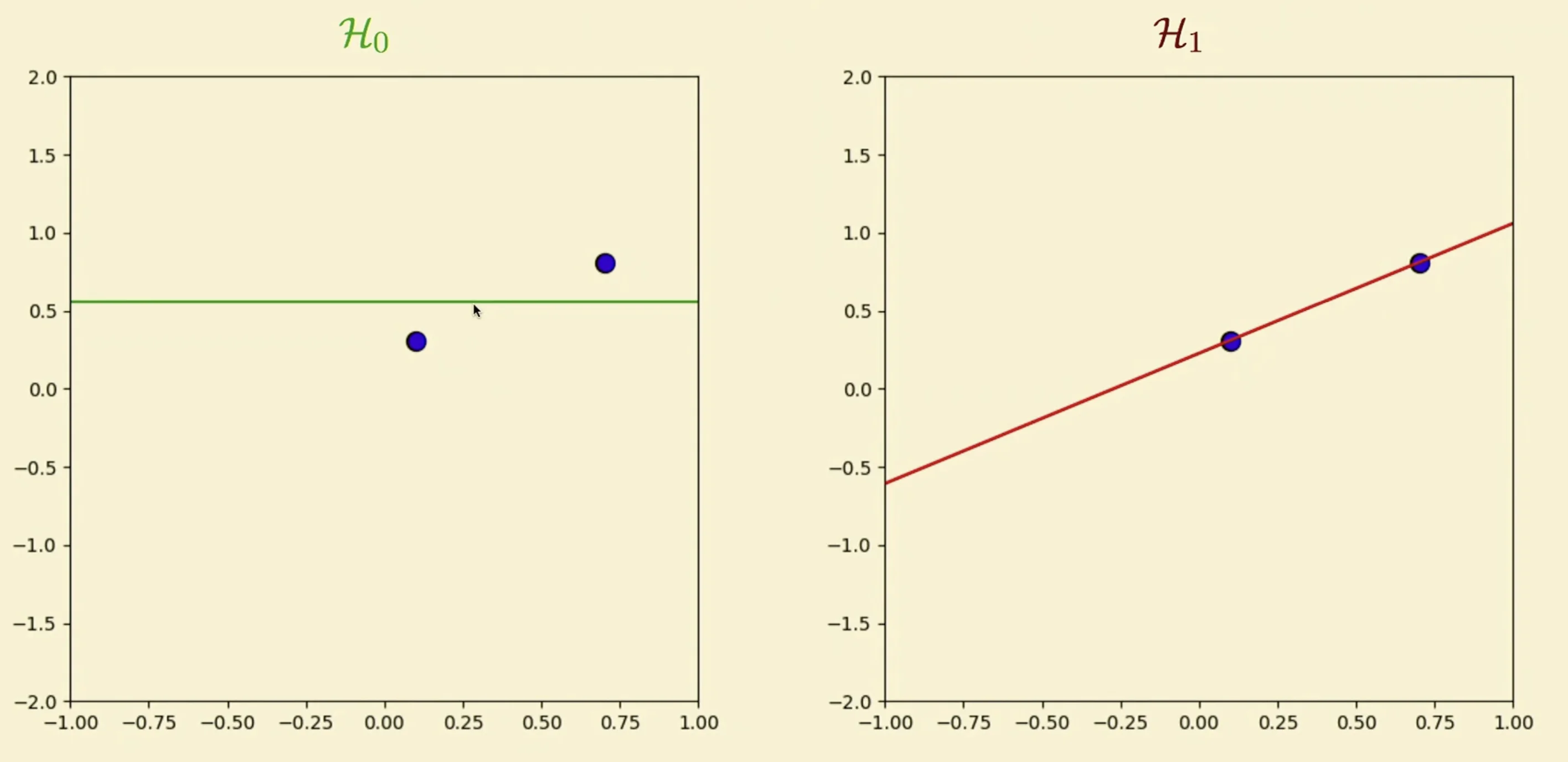
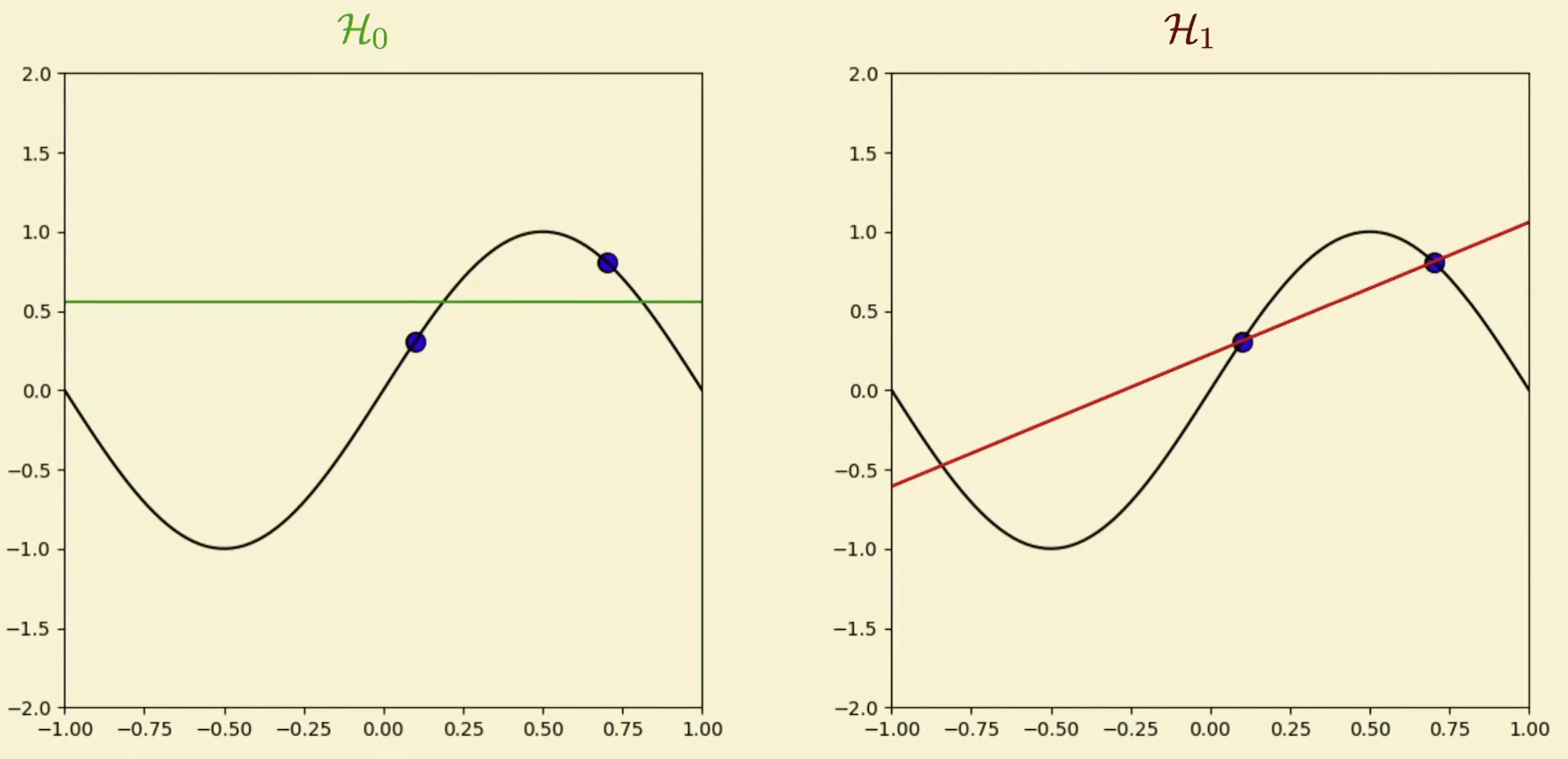
- Which one is better? We don’t know as it depends on what are the initial two data points given. Therefore, we need the bias variance method for us to determine which method produces less error.
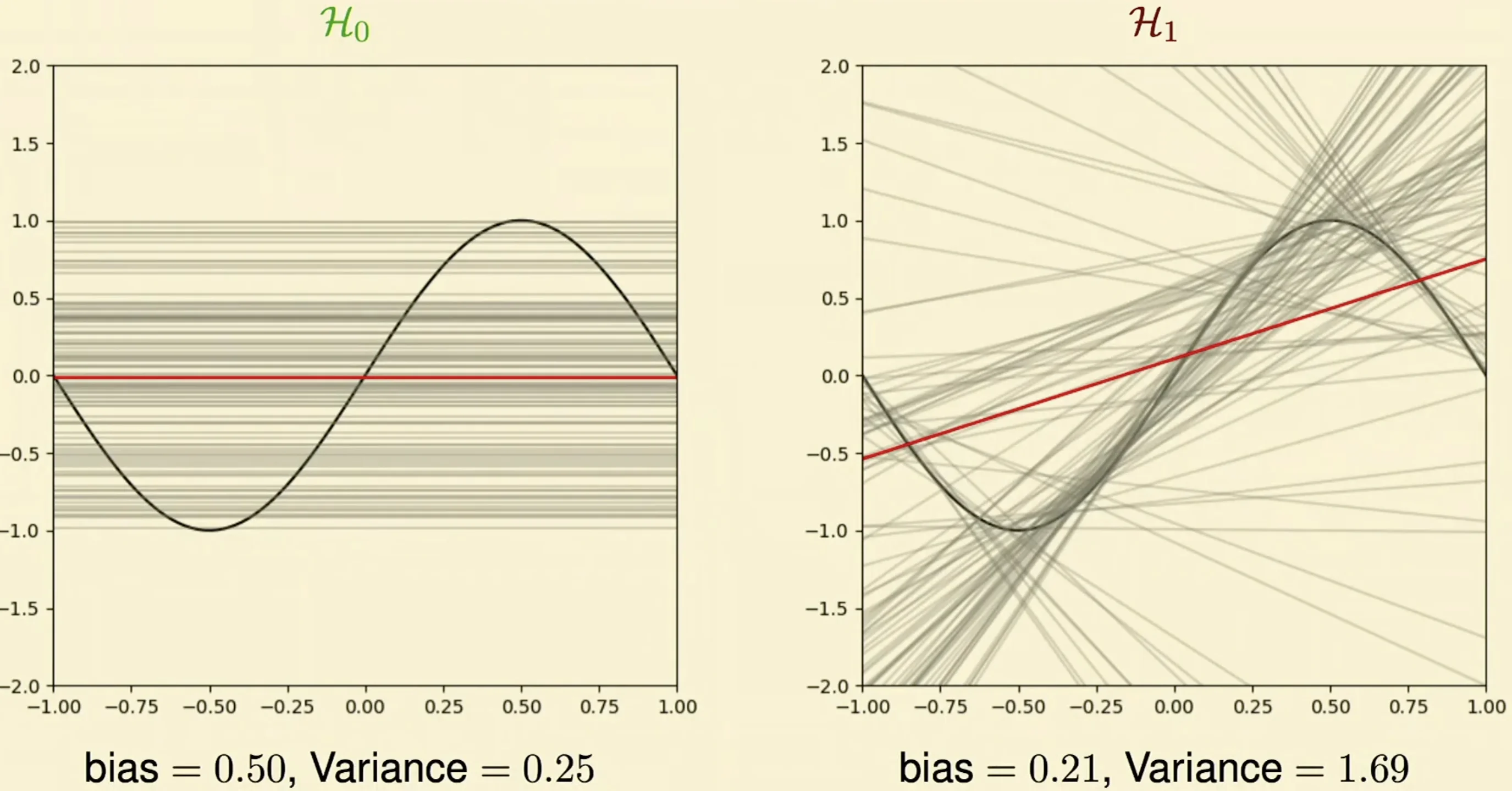
Bias Variance
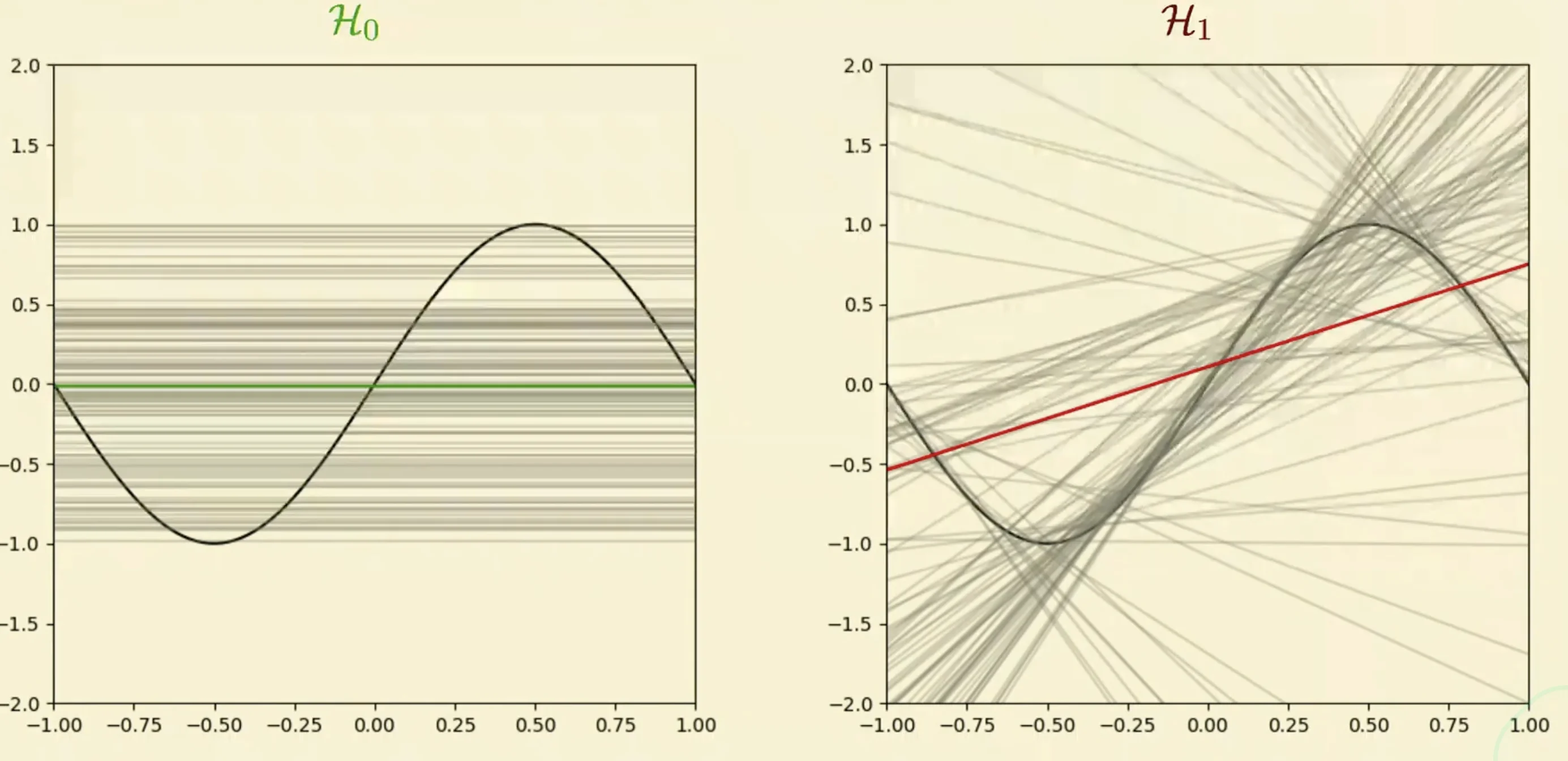
- From each possible models, we calculate the expected model (mean)
- From the mean model, we calculate the variance and the bias
Learning in Practice
- more training examples with noise
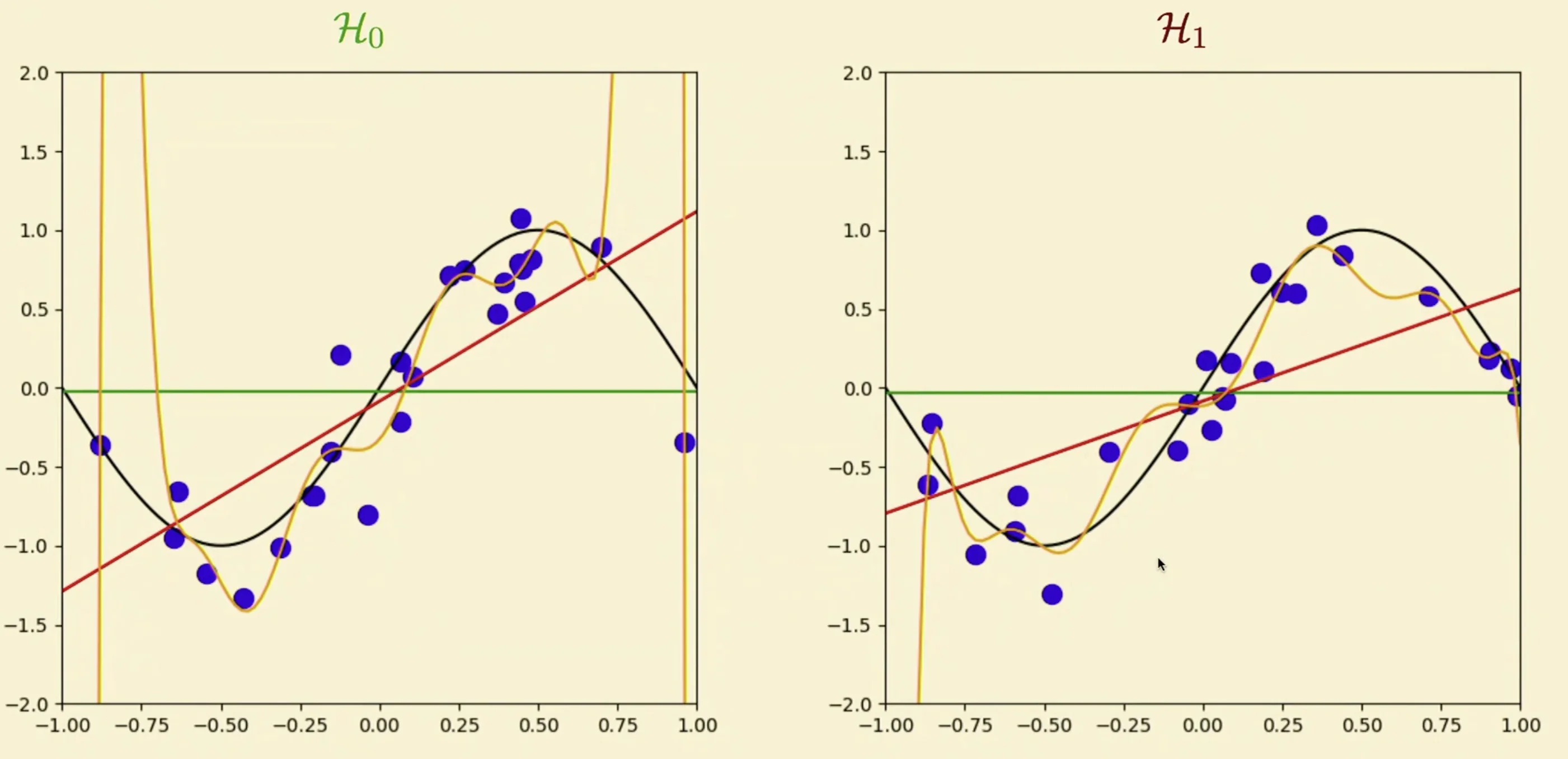
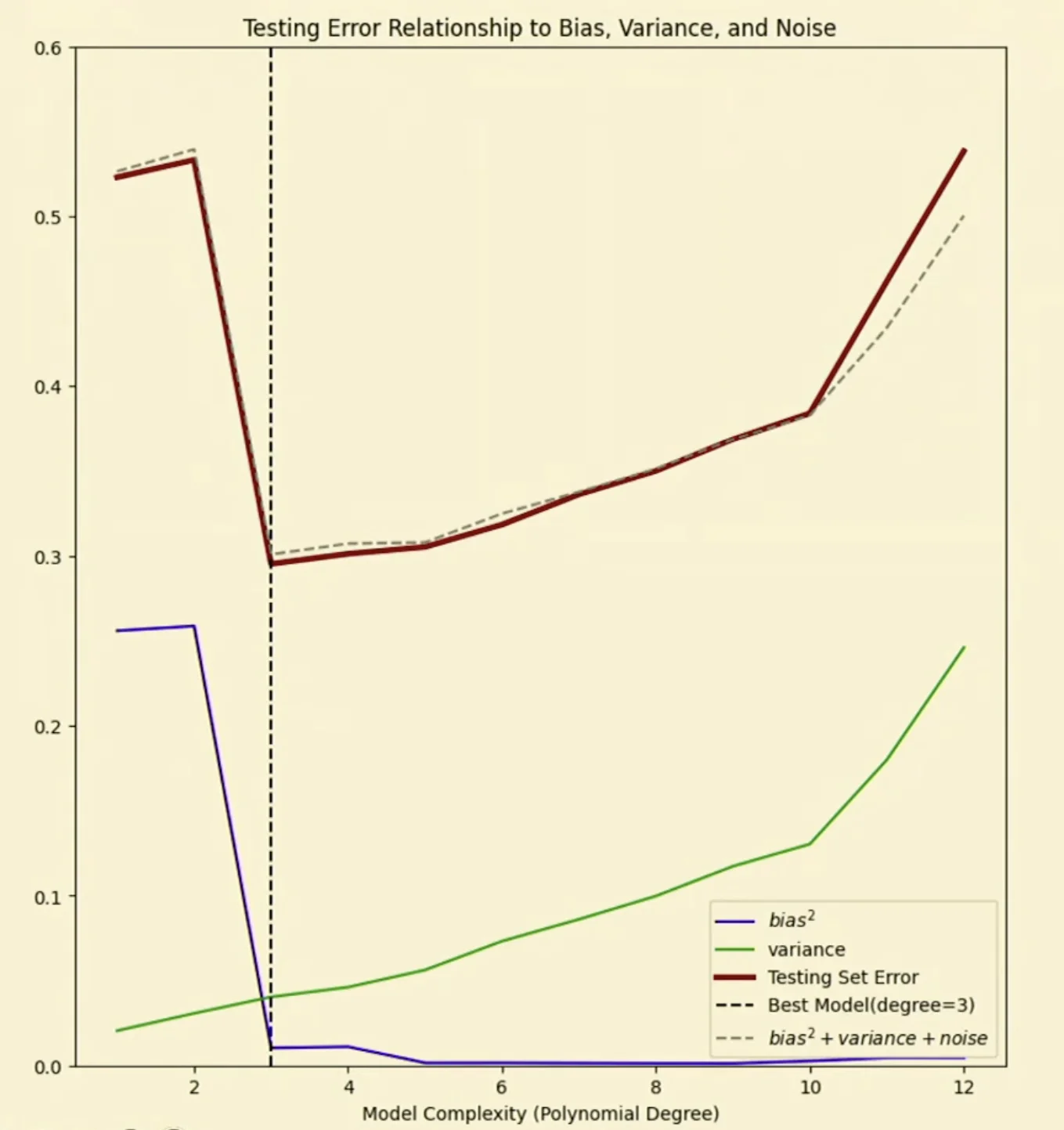
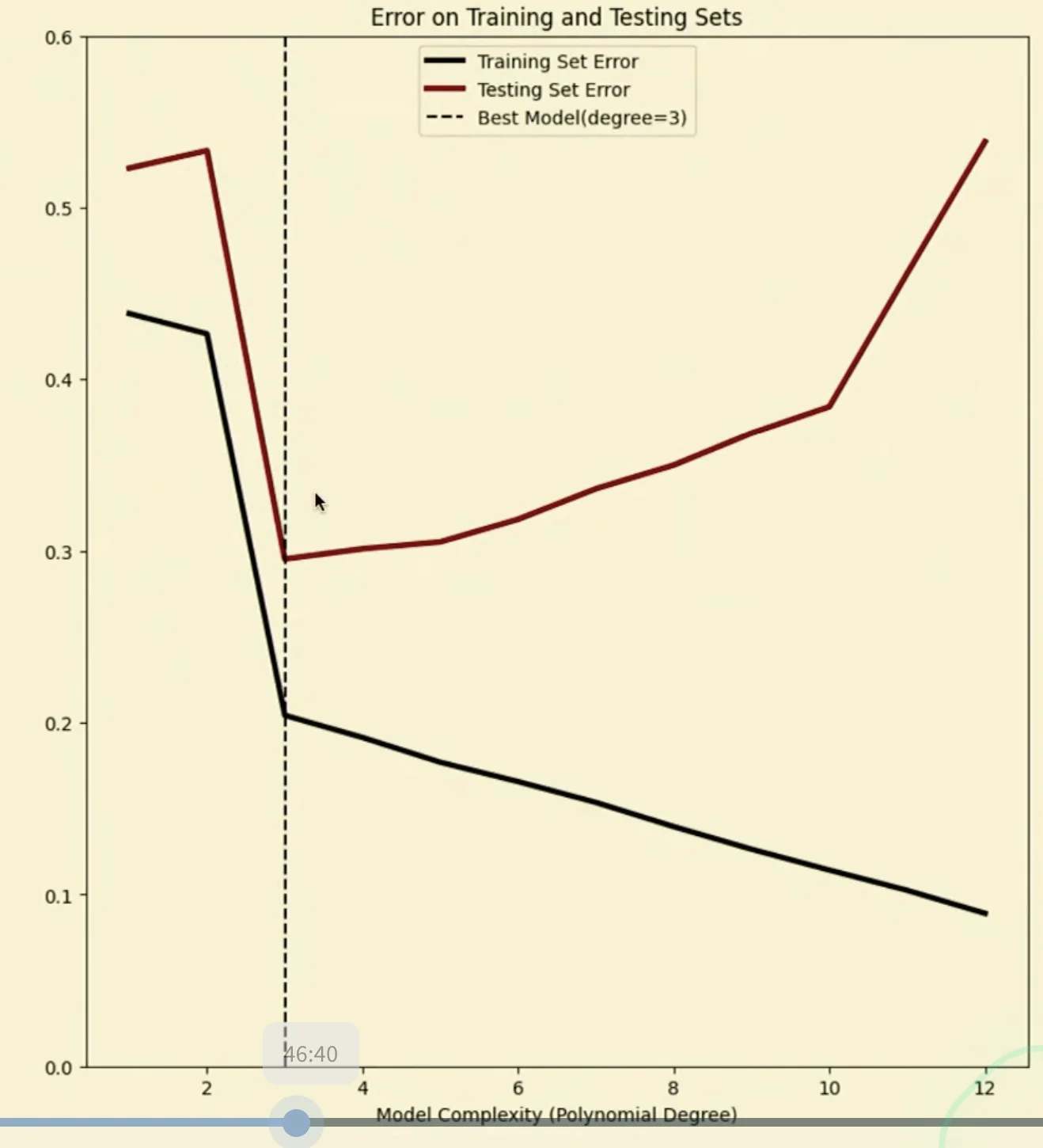
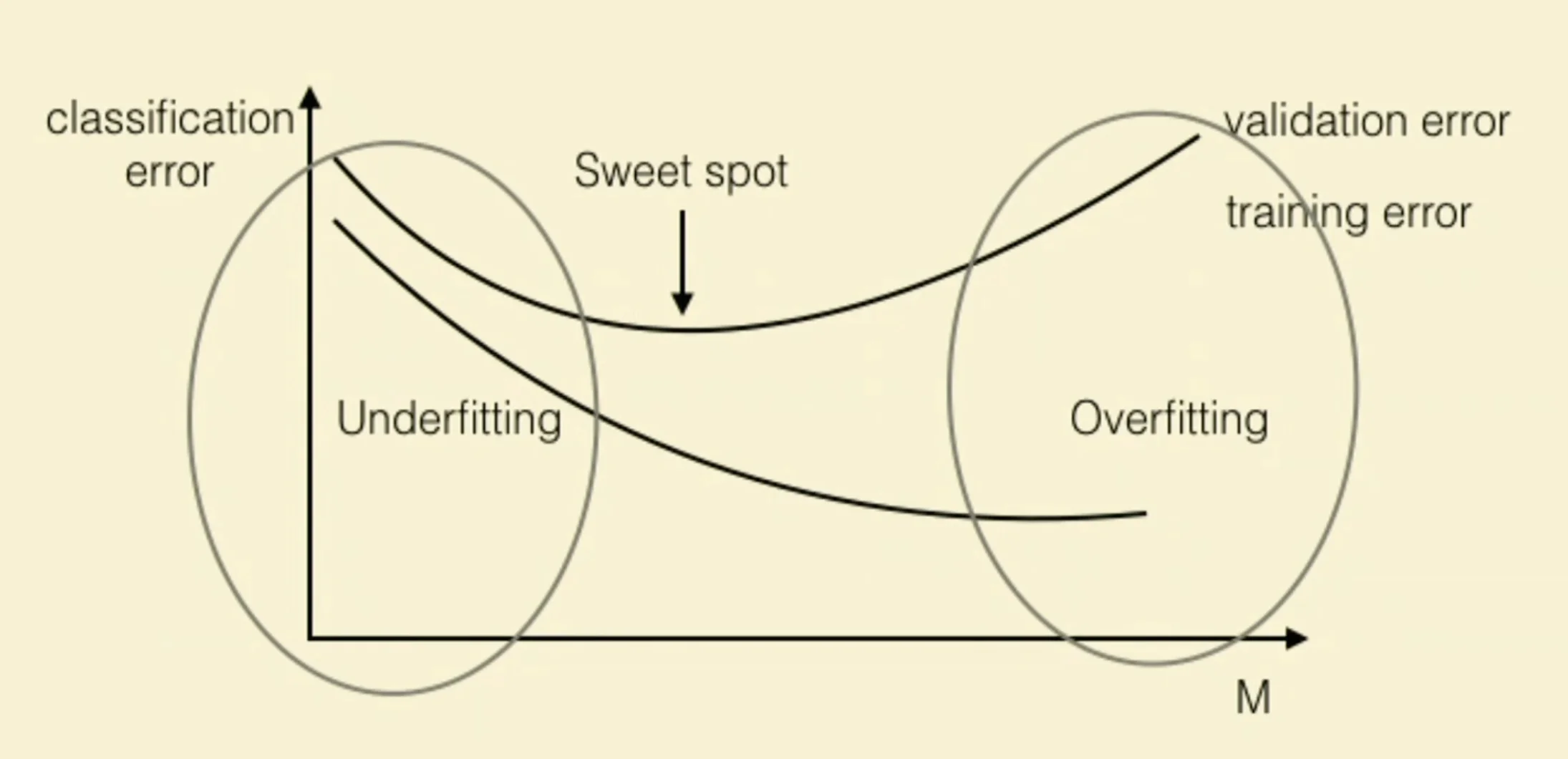
- Models to the left of best model may underfit
- Models to the right of the best model may overfit
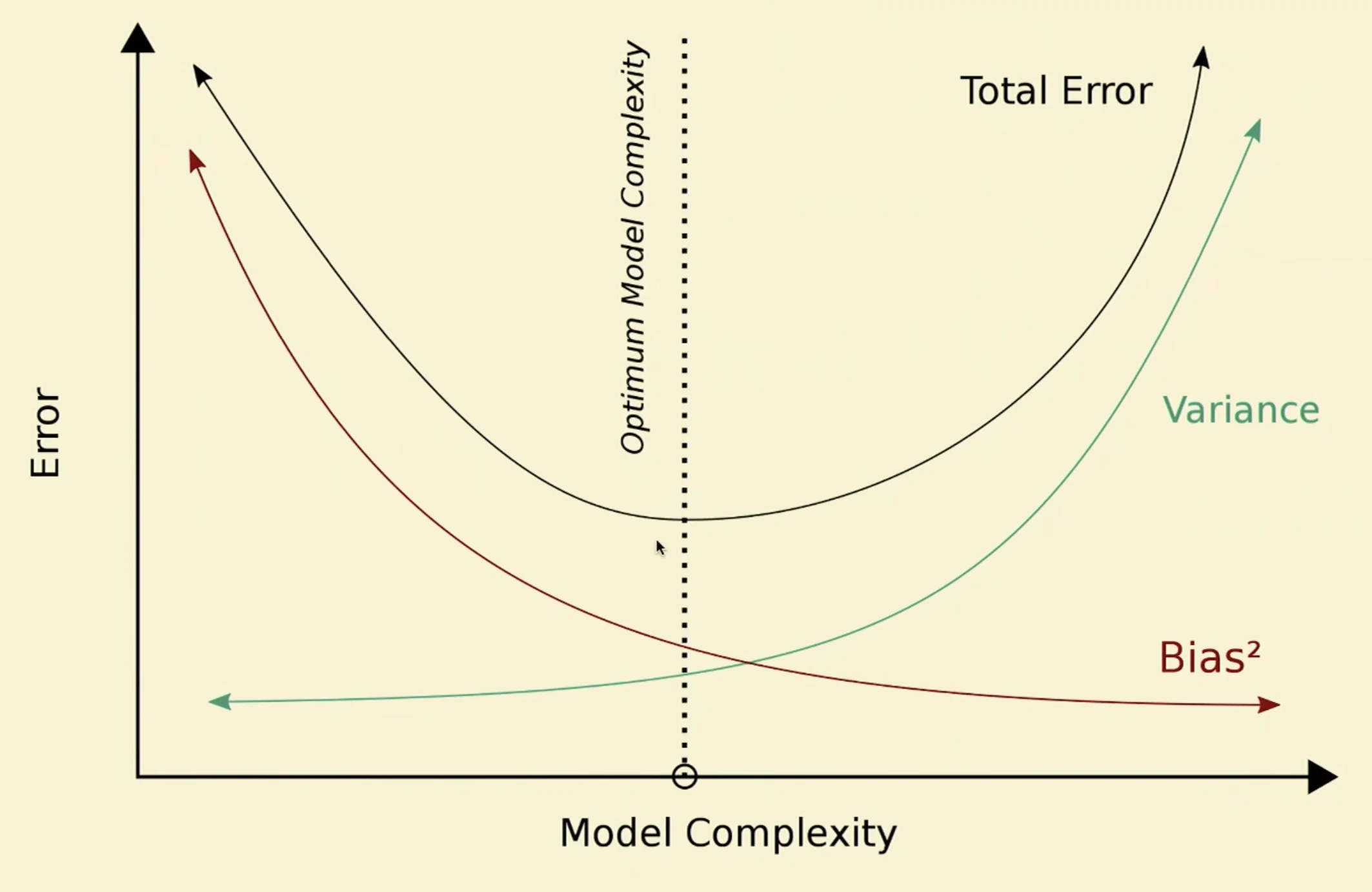
REM and Overfitting and Underfitting
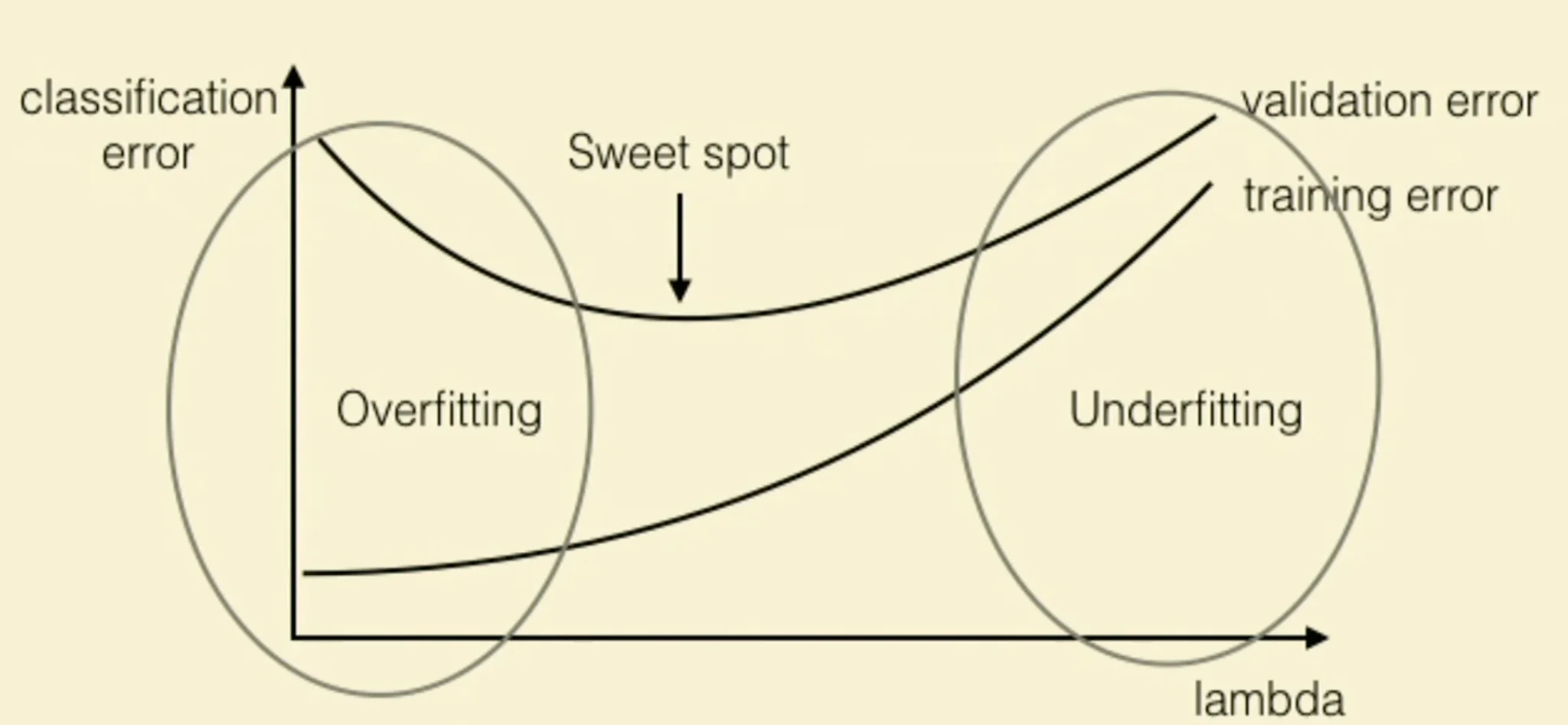
Important
Hoow to identify the sweet spot?
Hold-out Method
How
- Can judge test error by using an independent sample of data
- Split data into training set and validation set
- Use the two sets for training and testing respectively.
Important
Telescopic Search
Find the best order of magnitude
Drawback
- May not have enough data to afford setting one subset aside for getting generalizability
- Validation error may be misleading (bad estimate of test error) if we get an unfortunate split
K-Fold Cross-Validation
- Create
K-foldpartition of the dataset
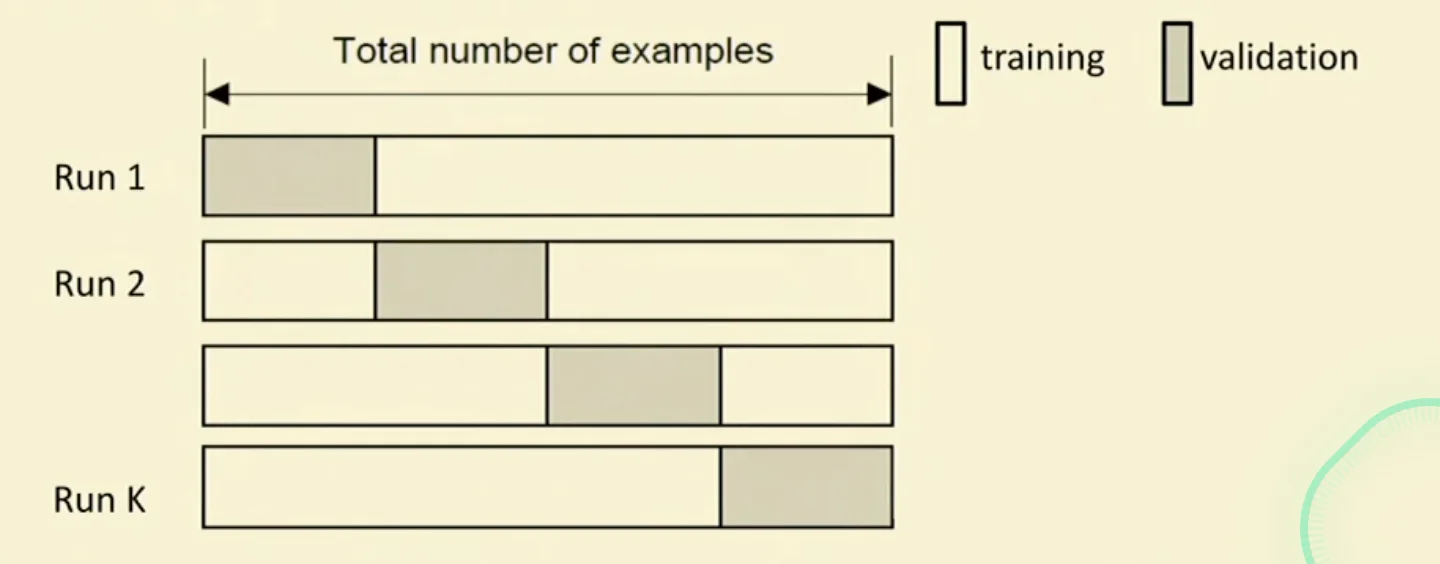
- Train using partitions and calculate the validation error using the remaining partition
Large K
- Validation error can approximate test error well
- Observed validation error will be unstable (few validation points)
- The computational time will be very large as well
Small K
- The # of runs and computational time are reduced
- Observed validation error will be stable
- Validation error cannot approximate test error well
Tip
is a common choice.
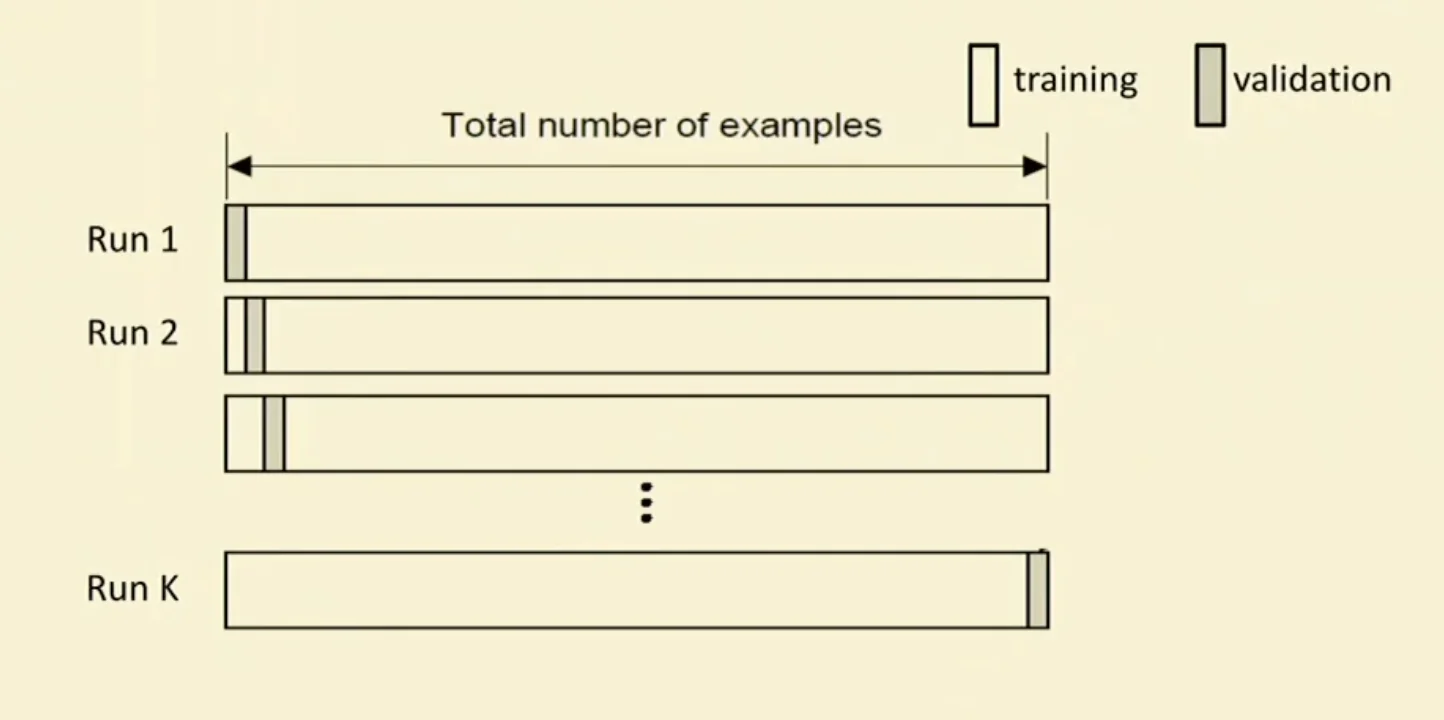
Leave-One-Out (LOO) Cross-Validation
- Special case of K-fold validation with partitions
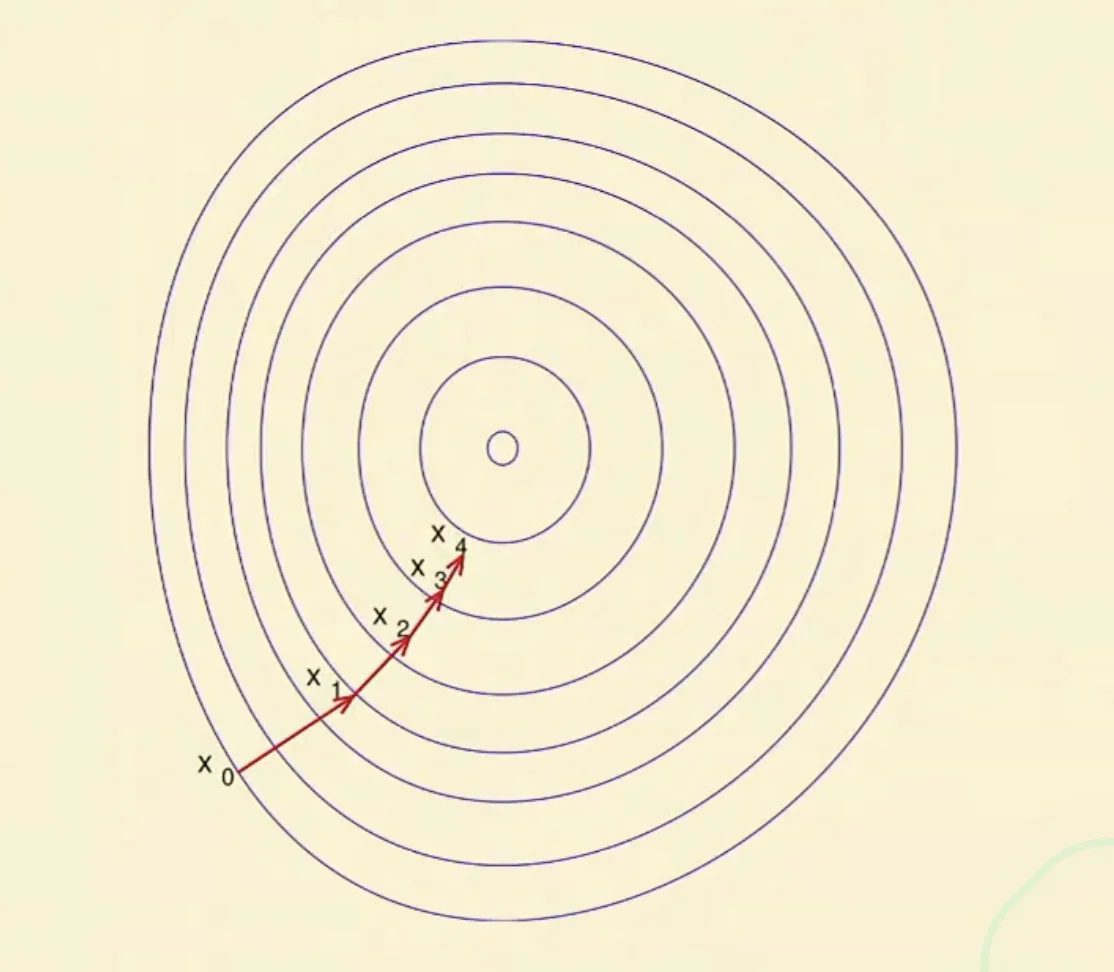
Early Stopping
- Stop your optimization after number of gradient steps, even if optimization has not converged yet.
What’s the connection between early stopping and regularization?
Early Stopping
Regularization
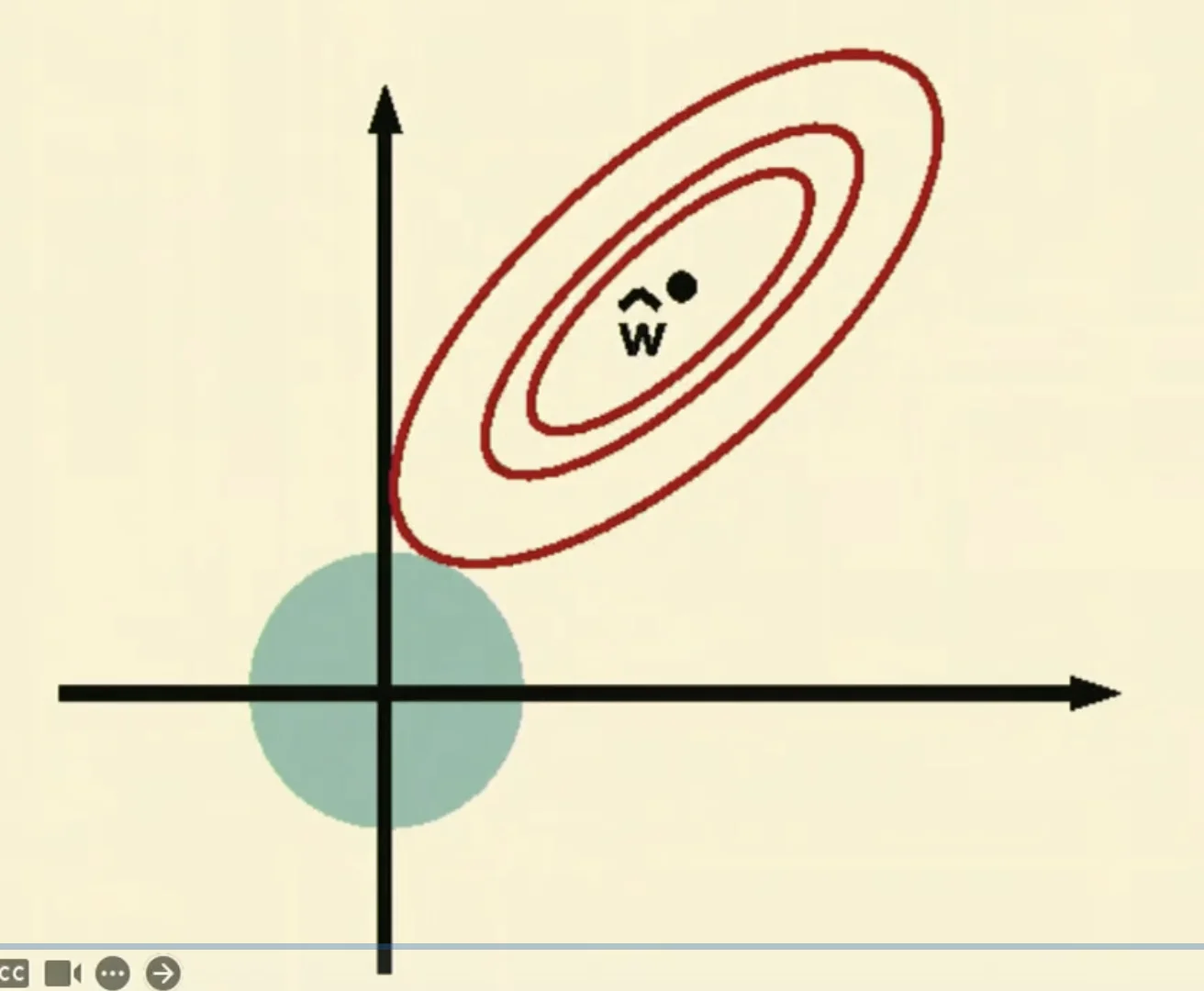
- Regularization restricts the predictions going outside of the green area.
The plot of early stopping
Think about the variance
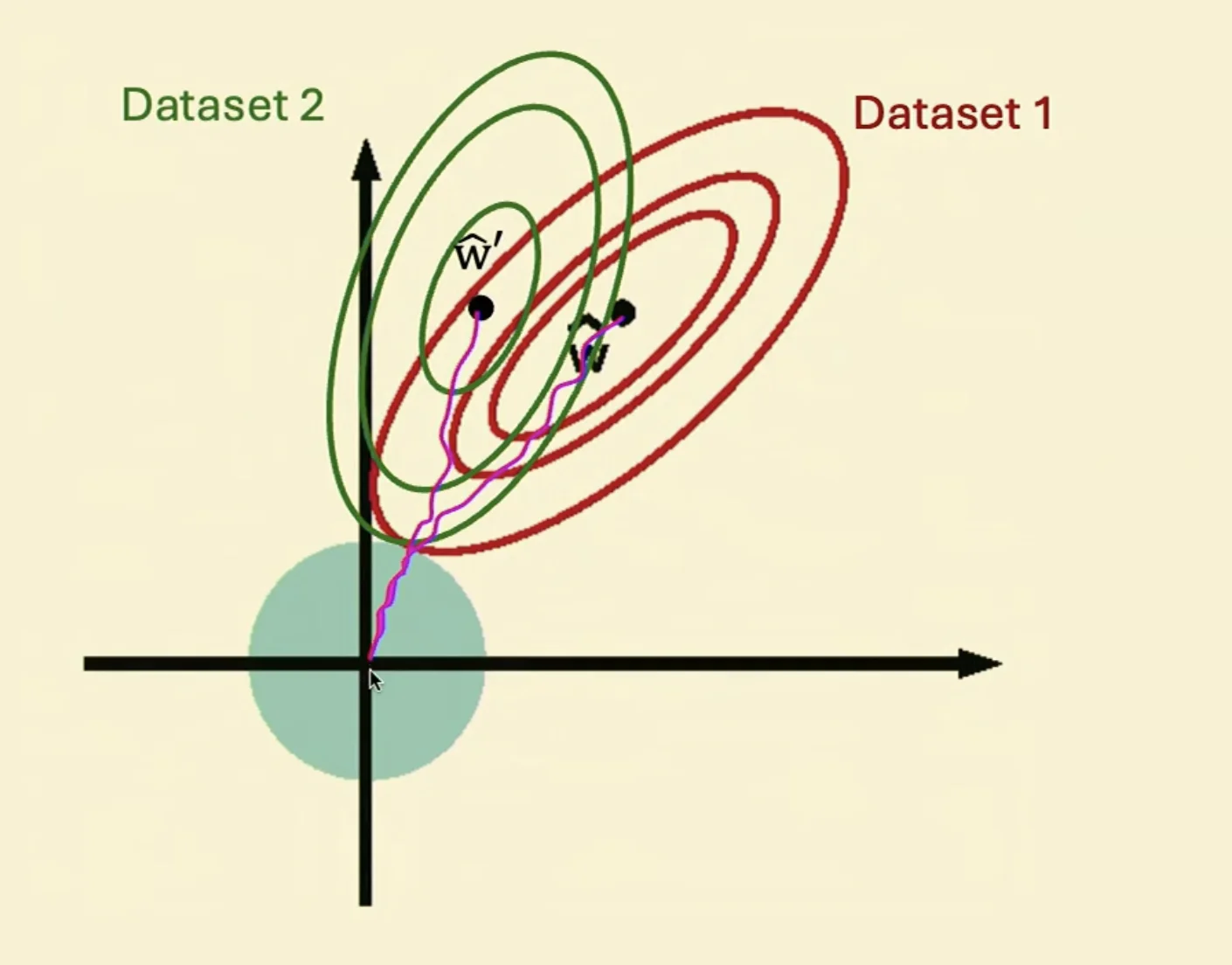
- If we stop early, we can stop the variance caused by different dataset